The state of cloud GPUs in 2025: costs, performance, playbooks¶
This is a practical map for teams renting GPUs — whether you’re a single project team fine-tuning models or a production-scale team managing thousand-GPU workloads. We’ll break down where providers fit, what actually drives performance, how pricing really works, and how to design a control plane that makes multi-cloud not just possible, but a competitive advantage.
A quick map of the market¶
Two forces define the market: Target scale (from single nodes → racks → multi-rack pods) and automation maturity (manual VMs → basic Kubernetes → API-first orchestration).
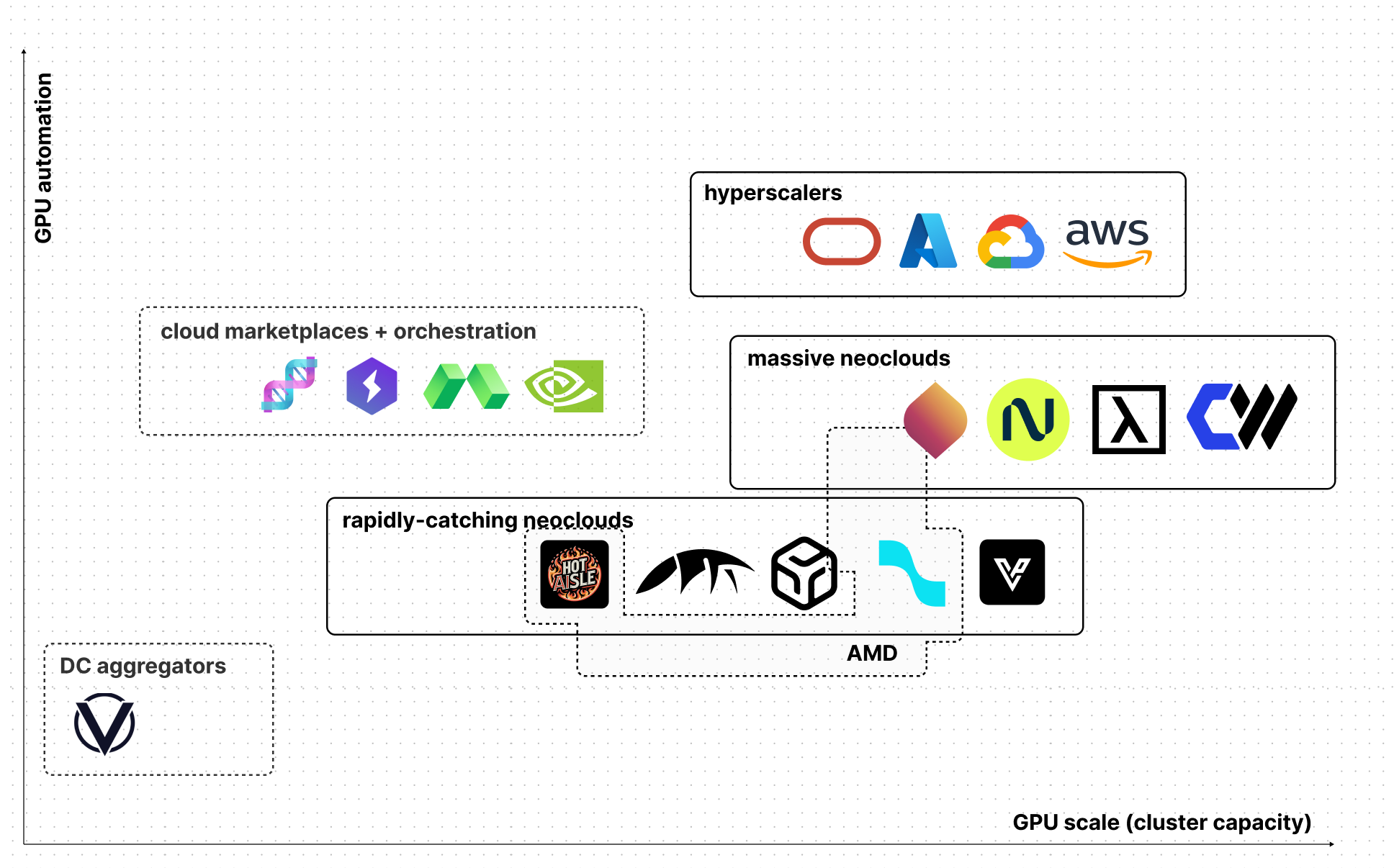
These axes split providers into distinct archetypes—each with different economics, fabrics, and operational realities.
Categories at a glance¶
| Category | Description | Examples |
|---|---|---|
| Classical hyperscalers | General-purpose clouds with GPU SKUs bolted on | AWS, Google Cloud, Azure, OCI |
| Massive neoclouds | GPU-first operators built around dense HGX or MI-series clusters | CoreWeave, Lambda, Nebius, Crusoe |
| Rapidly-catching neoclouds | Smaller GPU-first players building out aggressively | Runpod, DataCrunch, Voltage Park, TensorWave, Hot Aisle |
| Cloud marketplaces | Don’t own capacity; sell orchestration + unified API over multiple backends | NVIDIA DGX Cloud (Lepton), Modal, Lightning AI, dstack Sky |
| DC aggregators | Aggregate idle capacity from third-party datacenters, pricing via market dynamics | Vast.ai |
Massive neoclouds lead at extreme GPU scales. Hyperscalers may procure GPU capacity from these GPU-first operators for both training and inference.
Silicon reality check¶
NVIDIA remains the path of least resistance for most teams—CUDA and the NVIDIA Container Toolkit still lead in framework compatibility and tooling maturity. H100 is now table stakes and widely available across clouds, a reflection of billions in GPU capex flowing into the open market. GB200 takes it further with tightly coupled domains ideal for memory- and bandwidth-heavy prefill, while cheaper pools can handle lighter decode phases.
AMD has now crossed the viability threshold with ROCm 6/7—native PyTorch wheels, ROCm containers, and upstream support in vLLM/SGLang mean OSS stacks “Day 0” if you standardize ROCm images. MI300X (192 GB) and MI350X (288 GB HBM3E) match or exceed NVIDIA on per-GPU memory and are increasingly listed by neoclouds. The new MI355X further pushes boundaries—designed for rack-scale AI, it packs massive HBM3E pools in high-density systems for ultra-large model throughput.
TPUs and Trainium excel in tightly coupled training when you’re all-in on one provider, letting you amortize integration over years. The trade-offs—vendor lock-in, slower OSS support, and smaller ecosystems—make them viable mainly for multi-year, hyperscale workloads where efficiency outweighs migration cost.
AMD vs NVIDIA fit. MI300X matches H200 in capacity (192 GB vs 141 GB) but with more headroom for long-context prefill. MI325X (256 GB) is rolling out slowly, with many providers jumping to MI350X/MI355X (288 GB HBM3E). These top models exceed B200’s 192 GB, making them viable drop-ins where ROCm is ready; GB200/NVL still lead for ultra-low-latency collectives.
What you’re really buying¶
The GPU SKU is only one piece. Real throughput depends on the system around it. Clusters are optional—until your workload forces them.
| Dimension | Why it matters | Examples |
|---|---|---|
| GPU memory | Governs max batch size and KV-cache headroom, reducing parallelism overhead. | H100 (80 GB), H200 (~141 GB), B200 (~192 GB), MI300X (192 GB), MI325X (256 GB), MI350X/MI355X (288 GB). |
| Fabric bandwidth | Dictates all-reduce speed and MoE routing efficiency. Matters beyond a few nodes | 400 Gb/s – 3.2 Tb/s (e.g., 8×400 Gb/s NICs) |
| Topology | Low-diameter, uniform interconnect pods beat ad-hoc multi-rack for scale efficiency | HGX islands |
| Local NVMe | NVMe hides object-store latency for shards and checkpoints | Multi-TB local SSD per node is common on training SKUs |
| Network volumes | Removes “copy to every node” overhead | FSx for Lustre, Filestore, managed NFS; in HPC/neocloud setups, Vast and Weka are common. |
| Orchestration | Containers, placement, gang scheduling, autoscaling | K8s+Kueue, KubeRay, dstack, SLURM, vendor schedulers |
Pricing models – and what they hide¶
Price tables don’t show availability risk. Commitments lower cost and increase odds you get the hardware when you need it.
| With commitments | No committments |
|---|---|
| Long-term (1–3 years) Reserved or savings plans. 30–70% below on-demand. High capacity assurance, but utilization risk if needs shift. | On-demand Launch instantly—if quota allows. Highest $/hr. Limited availability for hot SKUs. |
| Short-term (6–12 months) Private offers, common with neoclouds. 20–60% off. Often includes hard capacity guarantees. | Flex / queued Starts when supply frees up. Cheaper than on-demand; runs capped in duration. |
| Calendar capacity Fixed-date bookings (AWS Capacity Blocks, GCP Calendar). Guarantees start time for planned runs. | Spot / preemptible 60–90% off. Eviction-prone; needs checkpointing/stateless design. |
Playbook
Lock in calendar or reserved for steady base load or planned long runs. Keep urgent, interactive, and development/CI/CD work on on-demand. Push experiments and ephemeral runs to spot/flex. Always leave exit ramps to pivot to new SKUs.
Quotas, approvals, and the human factor¶
Even listed SKUs may be gated. Hyperscalers and neoclouds enforce quotas and manual approvals—region by region—especially for new accounts on credits. If you can’t clear those gates, multi-cloud isn’t optional, it’s survival.
H100 pricing example¶
Below is the price range for a single H100 SXM across providers.
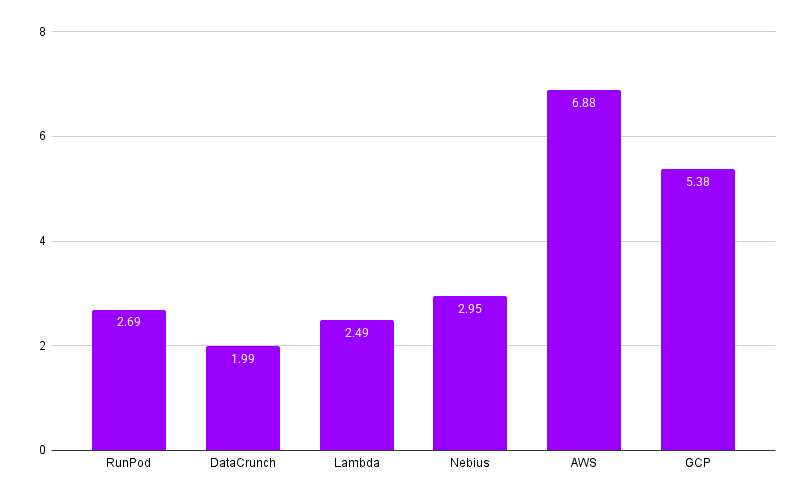
Price is per GPU and excludes full CPU, disk amount and type, and network factors. 8xGPU multi-node setups with fast interconnects will cost more.
For comparison, below is the price range for H100×GPU clusters across providers.
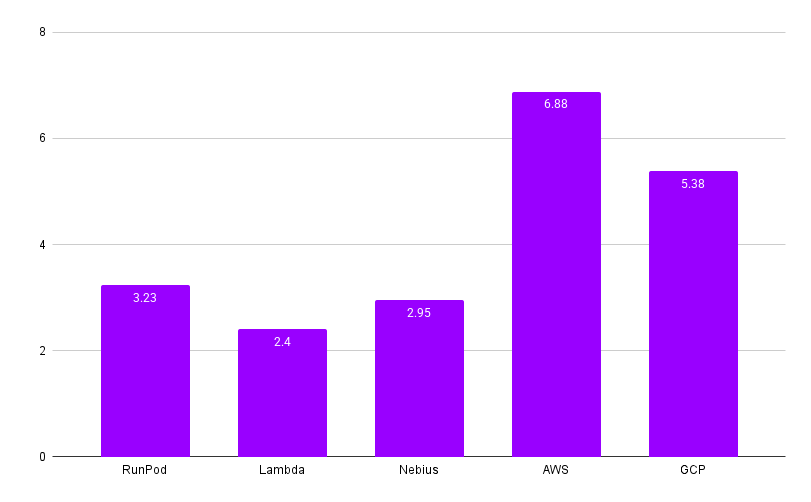
Most hyperscalers and neoclouds need short- or long-term contracts, though providers like Runpod, DataCrunch, and Nebius offer on-demand clusters. Larger capacity and longer commitments bring bigger discounts — Nebius offers up to 35% off for longer terms.
New GPU generations – why they matter¶
- Memory and bandwidth scaling. Higher HBM and faster interconnects expand batch size, context length, and per-node throughput. NVIDIA’s B300 and AMD’s MI355X push this further with massive HBM3E capacity and rack-scale fabrics, targeting ultra-large training runs.
- Fabrics. Each new generation often brings major interconnect upgrades — GB200 with NVLink5 (1.8 TB/s) and 800 Gb/s Infiniband, MI355X with PCIe Gen6 and NDR. These cut all-reduce and MoE latency, but only if the cloud deploys matching network infrastructure. Pairing new GPUs with legacy 400 Gb/s links can erase much of the gain.
- Prefill vs decode. Prefill (memory/bandwidth heavy) thrives on large HBM and tightly coupled GPUs like GB200 NVL72. Decode can run cheaper, on high-concurrency pools. Splitting them is a major cost lever.
- Cascade. Top-end SKUs arrive roughly every 18–24 months, with mid-cycle refreshes in between. Each launch pushes older SKUs down the price curve — locking in for years right before a release risks overpaying within months.
Prices
H100 prices have dropped significantly in recent years due to new GPU generations and models like DeepSeek that require more memory. New generations include the H200 and B200. Only AWS has reduced H100 instance prices by 44%. H200 and later B200 prices are expected to follow the same trend.
AMD MI300X pricing is also softening as MI350X/MI355X roll out, with some neoclouds undercutting H100/H200 on $/GPU-hr while offering more memory per GPU.
Where provisioning is going¶
The shift is from ad-hoc starts to time-bound allocations.
Large runs are booked ahead; daily work rides elastic pools. Placement engines increasingly decide on region + provider + interconnect before SKU. The mindset moves from “more GPUs” to “higher sustained utilization.”
Control plane as the force multiplier¶
A real multi-cloud control plane should:
- Be quota-aware and cost-aware – place jobs where they’ll start fastest at the best $/SLO.
- Maximize utilization – keep GPUs busy with checkpointing, resumable pipelines, and efficient gang scheduling.
- Enforce portability – one container spec, CUDA+ROCm images, upstream framework compatibility, state in object storage.
This turns capacity from individual silos into one fungible pool.
Final takeaways¶
- Price ≠ cost — List price often explains <50% of total job cost on multi-node training; fabric and storage dominate at scale.
- Match commitments to workload reality — and leave room for next-gen hardware.
- Multi-cloud isn’t backup, it’s strategy – keep a warm secondary.
- Watch AMD’s ramp-up – the MI series is becoming production-ready, and MI355X availability is set to expand quickly as providers bring it online.
- Control plane is leverage – define once, run anywhere, at the cheapest viable pool.
Scope & limitations of this report
- Provider coverage. The vendor set is a curated sample aligned with the dstack team’s view of the market. A limited group of community members and domain experts reviewed drafts. Corrections, reproducibility notes, and additional data points are welcome.
- Methodology gaps. We did not perform cross-vendor price normalization (CPU/RAM/NVMe/fabric adjustments, region effects, egress), controlled microbenchmarks (NCCL/all-reduce, MoE routing latency, KV-cache behavior, object store vs. parallel FS), or a full orchestration capability matrix (scheduler semantics, gang scheduling, quota APIs, preemption, multi-tenancy).
- Next steps. We plan to publish price normalization, hardware/network microbenchmarks, and a scheduler capability matrix; preliminary harnesses are linked in the appendix. Contributors welcome.
If you need a lighter, simpler orchestration and control-plane alternative to Kubernetes or Slurm, consider dstack. It’s open-source and self-hosted.
dstack Sky
If you want unified access to low-cost on-demand and spot GPUs across multiple clouds, try dstack Sky.
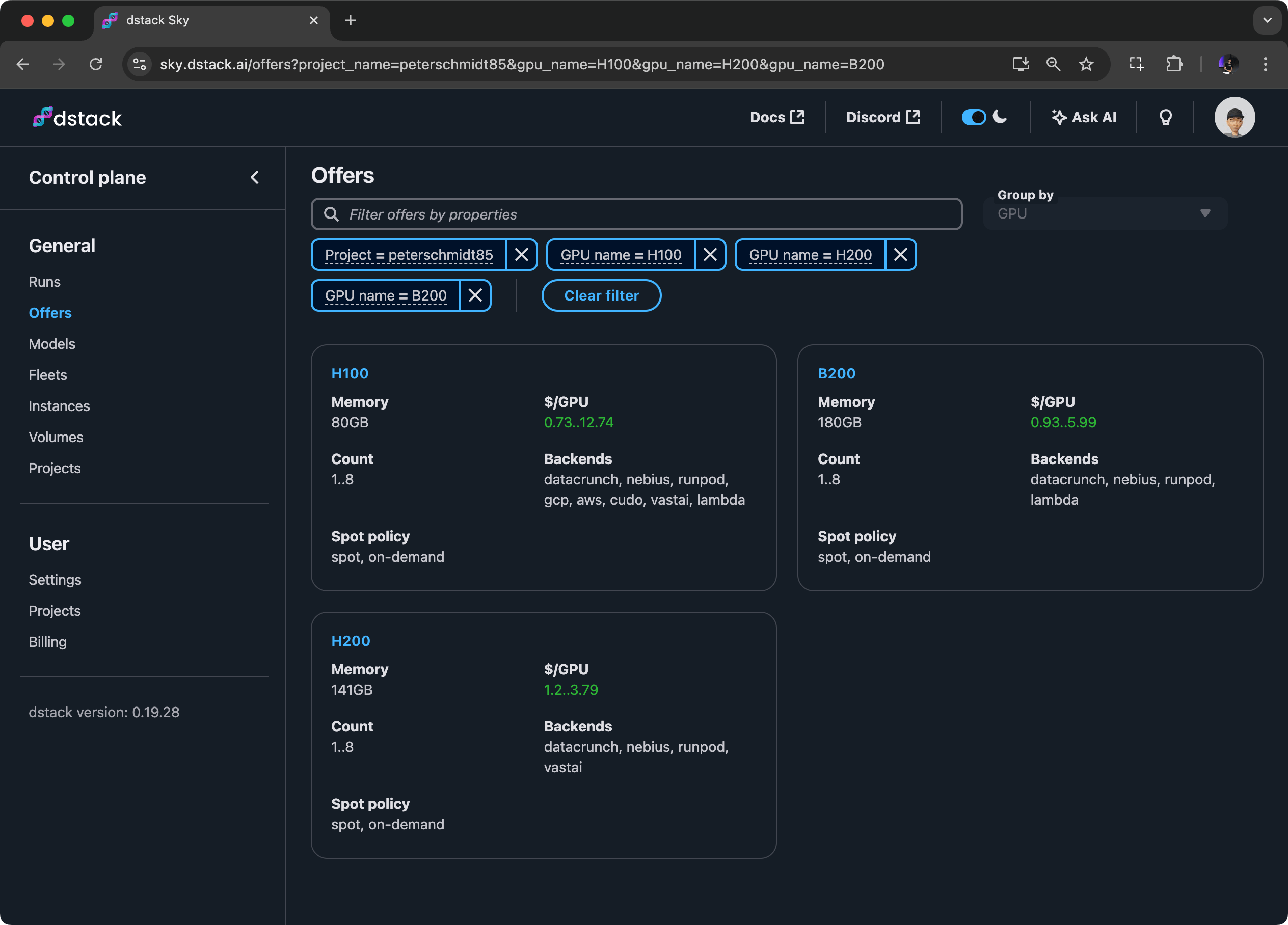
You can use it with your own cloud accounts or through the cloud marketplace.