Orchestrating GPUs on DigitalOcean and AMD Developer Cloud¶
Orchestration automates provisioning, running jobs, and tearing them down. While Kubernetes and Slurm are powerful in their domains, they lack the lightweight, GPU-native focus modern teams need to move faster.
dstack is built entirely around GPUs. Our latest update introduces native integration with DigitalOcean and
AMD Developer Cloud, enabling teams to provision cloud GPUs and run workloads more cost-efficiently.

About Digital Ocean¶
DigitalOcean is one of the leading cloud platforms offering GPUs both as VMs and as bare-metal clusters equipped with NVIDIA and AMD GPUs.
About AMD Developer Cloud¶
AMD Developer Cloud is a new cloud platform designed to make AMD GPUs easily accessible to developers, academics, open-source contributors, and AI innovators worldwide.
Why dstack¶
dstack provides a high-level, AI-engineer-friendly interface where GPUs work out of the box—no K8S custom operators or low-level setup required. It’s use-case agnostic, equally suited for training, inference, benchmarking, and dev environments.
With the new DigitalOcean and AMD Developer Cloud backends, you can now provision NVIDIA or AMD GPU VMs and run workloads with a single CLI command.
Getting started¶
Best part about dstack is that it's very easy to get started.
- Create a project in Digital Ocean or AMD Developer Cloud
- Get credits or approve a payment method
- Create an API key
Then, configure the backend in ~/.dstack/server/config.yml:
projects:
- name: main
backends:
- type: amddevcloud
project_name: my-amd-project
creds:
type: api_key
api_key: ...
For DigitalOcean, set type to digitalocean.
Install and start the dstack server:
$ pip install "dstack[server]"
$ dstack server
For more details, see Installation.
Use the dstack CLI to
manage dev environments, tasks,
and services.
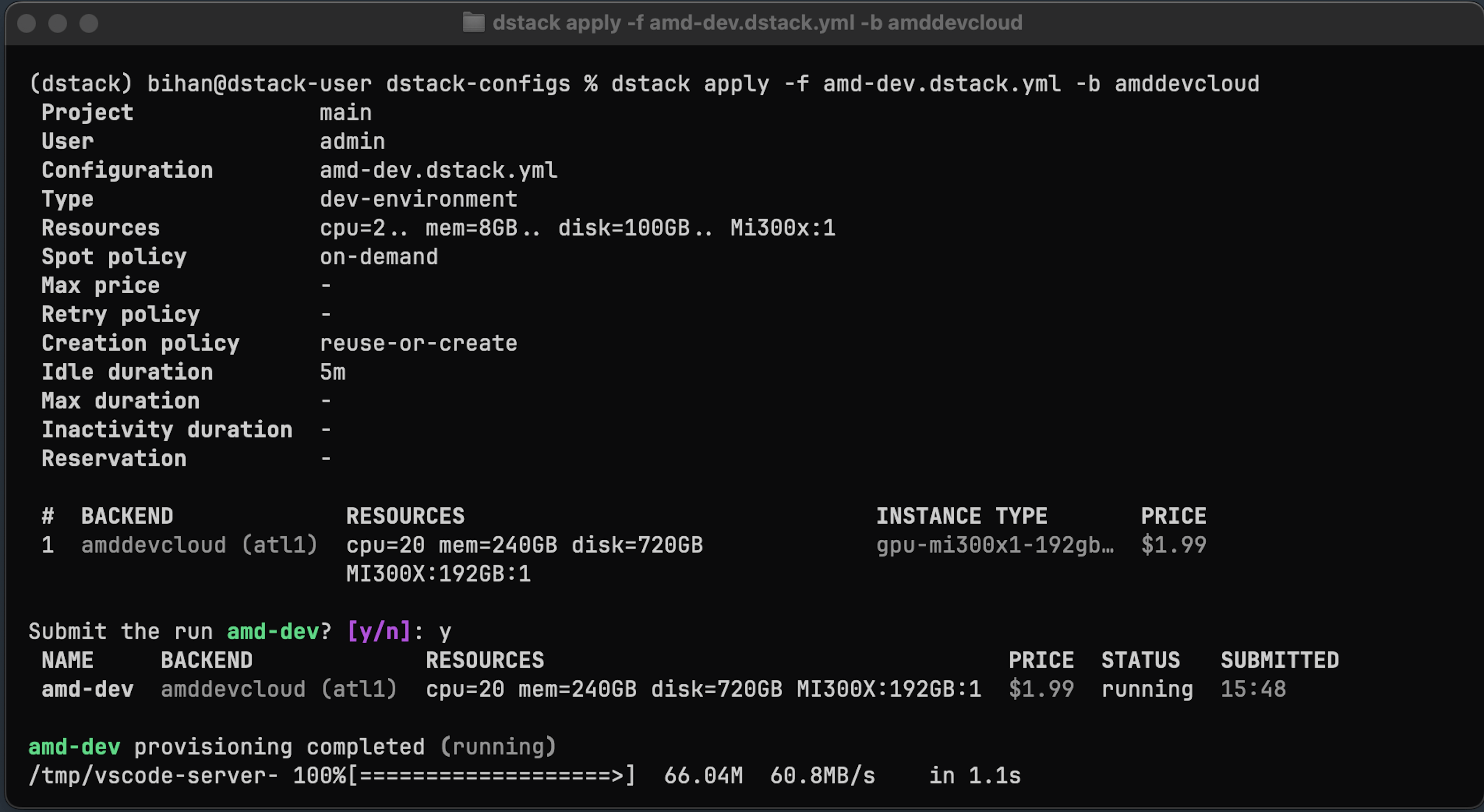
The digitalocean and amddevcloud backends support NVIDIA and AMD GPU VMs, respectively, and allow you to run
dev environments (interactive development), tasks
(training, fine-tuning, or other batch jobs), and services (inference).
Here’s an example of a service configuration:
type: service
name: gpt-oss-120b
model: openai/gpt-oss-120b
env:
- HF_TOKEN
- MODEL=openai/gpt-oss-120b
# To enable AITER, set below to 1. Otherwise, set it to 0.
- VLLM_ROCM_USE_AITER=1
# To enable AITER Triton unified attention
- VLLM_USE_AITER_UNIFIED_ATTENTION=1
# below is required in order to enable AITER unified attention by disabling AITER MHA
- VLLM_ROCM_USE_AITER_MHA=0
image: rocm/vllm-dev:open-mi300-08052025
commands:
- |
vllm serve $MODEL \
--tensor-parallel $DSTACK_GPUS_NUM \
--no-enable-prefix-caching \
--disable-log-requests \
--compilation-config '{"full_cuda_graph": true}'
port: 8000
volumes:
# Cache downloaded models
- /root/.cache/huggingface:/root/.cache/huggingface
resources:
gpu: MI300X:8
shm_size: 32GB
As with any configuration, you can apply it via dstack apply. If needed, dstack will automatically provision new VMs and run the inference endpoint.
$ dstack apply -f examples/models/gpt-oss/120b.dstack.yml
# BACKEND RESOURCES PRICE
1 amddevcloud (alt1) cpu=20 mem=240GB disk=720GB MI300X:192GB:8 $15.92
Submit the run? [y/n]:
If you prefer to use bare-metal clusters with
dstack, you can create an SSH fleet. This way, you’ll be able to run distributed tasks efficiently across the cluster.
What's next?
- Check Quickstart
- Learn more about DigitalOcean and AMD Developer Cloud
- Explore dev environments, tasks, services, and fleets
- Join Discord