Tenstorrent¶
dstack supports running dev environments, tasks, and services on Tenstorrent
Wormwhole accelerators via SSH fleets.
SSH fleets
type: fleet
name: wormwhole-fleet
ssh_config:
user: root
identity_file: ~/.ssh/id_rsa
# Configure any number of hosts with n150 or n300 PCEe boards
hosts:
- 192.168.2.108
Hosts should be pre-installed with Tenstorrent software. This should include the drivers,
tt-smi, and HugePages.
To apply the fleet configuration, run:
$ dstack apply -f examples/acceleators/tenstorrent/fleet.dstack.yml
FLEET RESOURCES PRICE STATUS CREATED
wormwhole-fleet cpu=12 mem=32GB disk=243GB n150:12GB $0 idle 18 sec ago
For more details on fleet configuration, refer to SSH fleets.
Services¶
Here's an example of a service that deploys
Llama-3.2-1B-Instruct
using Tenstorrent Inference Service.
type: service
name: tt-inference-server
env:
- HF_TOKEN
- HF_MODEL_REPO_ID=meta-llama/Llama-3.2-1B-Instruct
image: ghcr.io/tenstorrent/tt-inference-server/vllm-tt-metal-src-release-ubuntu-20.04-amd64:0.0.4-v0.56.0-rc47-e2e0002ac7dc
commands:
- |
. ${PYTHON_ENV_DIR}/bin/activate
pip install "huggingface_hub[cli]"
export LLAMA_DIR="/data/models--$(echo "$HF_MODEL_REPO_ID" | sed 's/\//--/g')/"
huggingface-cli download $HF_MODEL_REPO_ID --local-dir $LLAMA_DIR
python /home/container_app_user/app/src/run_vllm_api_server.py
port: 7000
model: meta-llama/Llama-3.2-1B-Instruct
# Cache downloaded model
volumes:
- /mnt/data/tt-inference-server/data:/data
resources:
gpu: n150:1
Go ahead and run configuration using dstack apply:
$ dstack apply -f examples/acceleators/tenstorrent/tt-inference-server.dstack.yml
Once the service is up, it will be available via the service endpoint
at <dstack server URL>/proxy/services/<project name>/<run name>/.
$ curl http://127.0.0.1:3000/proxy/services/main/tt-inference-server/v1/chat/completions \
-X POST \
-H 'Authorization: Bearer <dstack token>' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta-llama/Llama-3.2-1B-Instruct",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is Deep Learning?"
}
],
"stream": true,
"max_tokens": 512
}'
Additionally, the model is available via dstack's control plane UI:
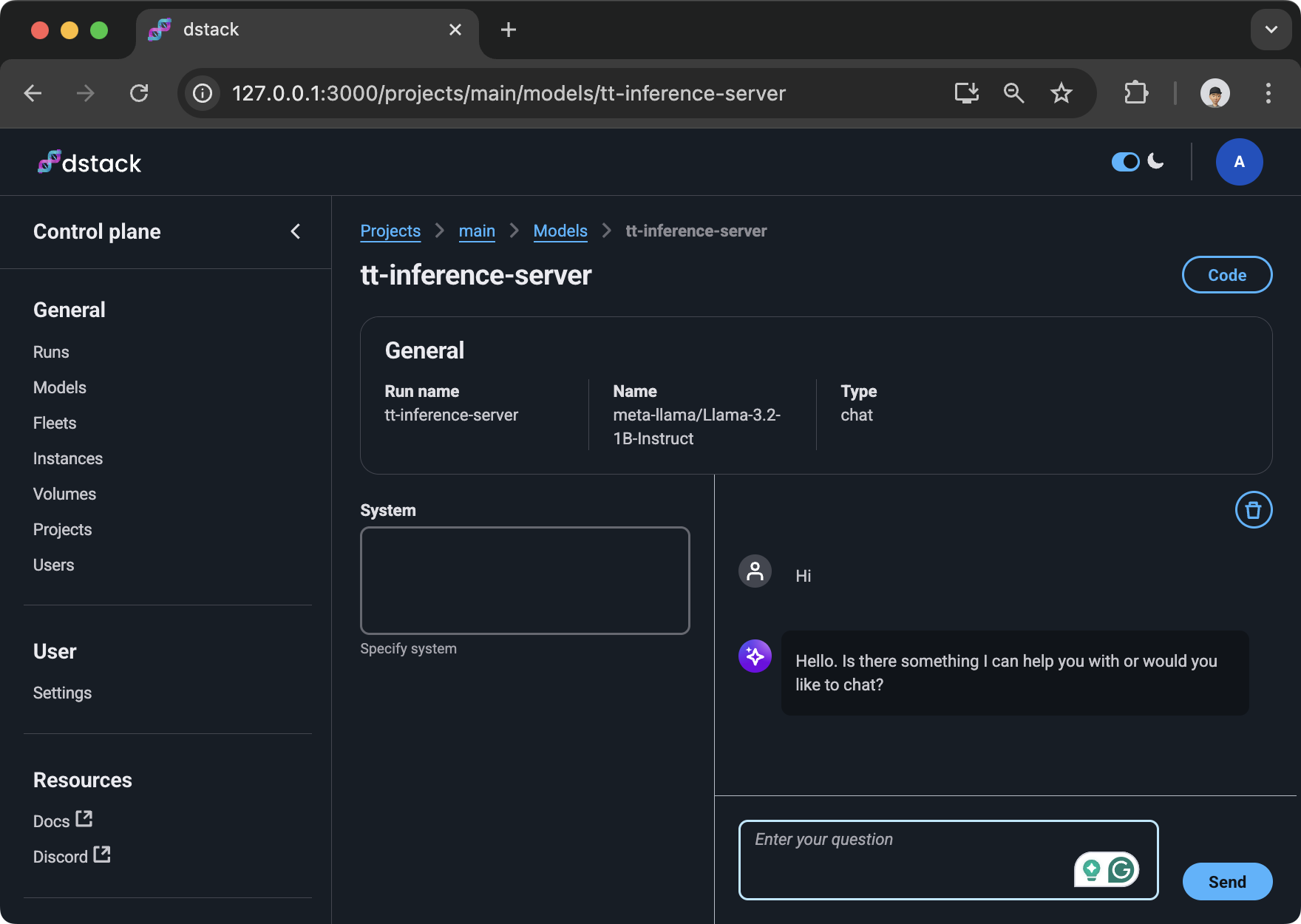
When a gateway is configured, the service endpoint
is available at https://<run name>.<gateway domain>/.
Services support many options, including authentication, auto-scaling policies, etc. To learn more, refer to Services.
Tasks¶
Below is a task that simply runs tt-smi -s. Tasks can be used for training, fine-tuning, batch inference, or antything else.
type: task
# The name is optional, if not specified, generated randomly
name: tt-smi
env:
- HF_TOKEN
# (Required) Use any image with TT drivers
image: dstackai/tt-smi:latest
# Use any commands
commands:
- tt-smi -s
# Specify the number of accelerators, model, etc
resources:
gpu: n150:1
# Uncomment if you want to run on a cluster of nodes
#nodes: 2
Tasks support many options, including multi-node configuration, max duration, etc. To learn more, refer to Tasks.
Dev environments¶
Below is an example of a dev environment configuration. It can be used to provision a dev environemnt that can be accessed via your desktop IDE.
type: dev-environment
# The name is optional, if not specified, generated randomly
name: cursor
# (Optional) List required env variables
env:
- HF_TOKEN
image: dstackai/tt-smi:latest
# Can be `vscode` or `cursor`
ide: cursor
resources:
gpu: n150:1
If you run it via dstack apply, it will output the URL to access it via your desktop IDE.
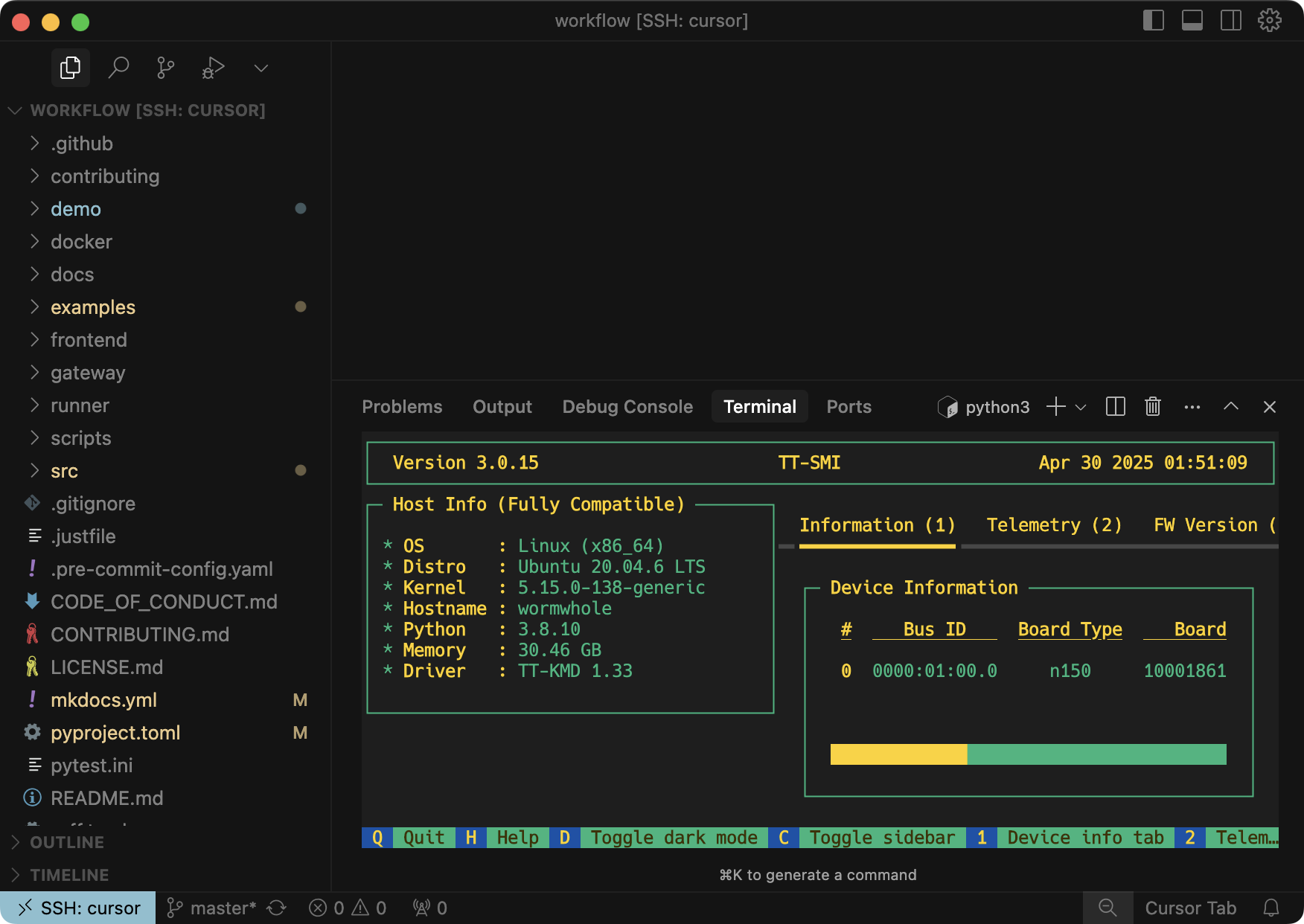
Dev nevironments support many options, including inactivity and max duration, IDE configuration, etc. To learn more, refer to Dev environments.
Feedback
Found a bug, or want to request a feature? File it in the issue tracker, or share via Discord.