Exploring inference memory saturation effect: H100 vs MI300x¶
GPU memory plays a critical role in LLM inference, affecting both performance and cost. This benchmark evaluates memory saturation’s impact on inference using NVIDIA's H100 and AMD's MI300x with Llama 3.1 405B FP8.
We examine the effect of limited parallel computational resources on throughput and Time to First Token (TTFT). Additionally, we compare deployment strategies: running two Llama 3.1 405B FP8 replicas on 4xMI300x versus a single replica on 4xMI300x and 8xMI300x
Finally, we extrapolate performance projections for upcoming GPUs like NVIDIA H200, B200, and AMD MI325x, MI350x.

This benchmark is made possible through the generous support of our friends at Hot Aisle and Lambda, who provided high-end hardware.
Benchmark setup¶
- AMD 8xMI300x
- 2x Intel Xeon Platinum 8470, 52C/104T, 16GT/s, 105M Cache (350W)
- 8x AMD MI300x GPU OAM, 192GB, 750W
- 32x 64GB RDIMM, 4800MT/s
- NVIDIA 8xH100 SXM5
- 2× Intel Xeon Platinum 8480+, 56C/112T, 16GT/s, 105M Cache (350W)
- 8× NVIDIA H100 SXM5 GPU, 80GB, 700W
- 32x 64GB DDR5
Benchmark modes¶
- Online inference: Benchmarked across QPS 16, 32, and 1000 using the ShareGPT dataset. Execution used vLLM’s benchmark_serving.
- Offline inference: Benchmarked with varying input/output lengths across different batch sizes, using vLLM’s benchmark_throughput.py.
| Input prompt lengths | Batch size | |
|---|---|---|
| Short/Small | 4 to 1024 | |
| Short/Large | 128 | 256 |
| Large/Large | 32784 | 64 (MI300x) / 16 (H100) |
Observations¶
Cost per token¶
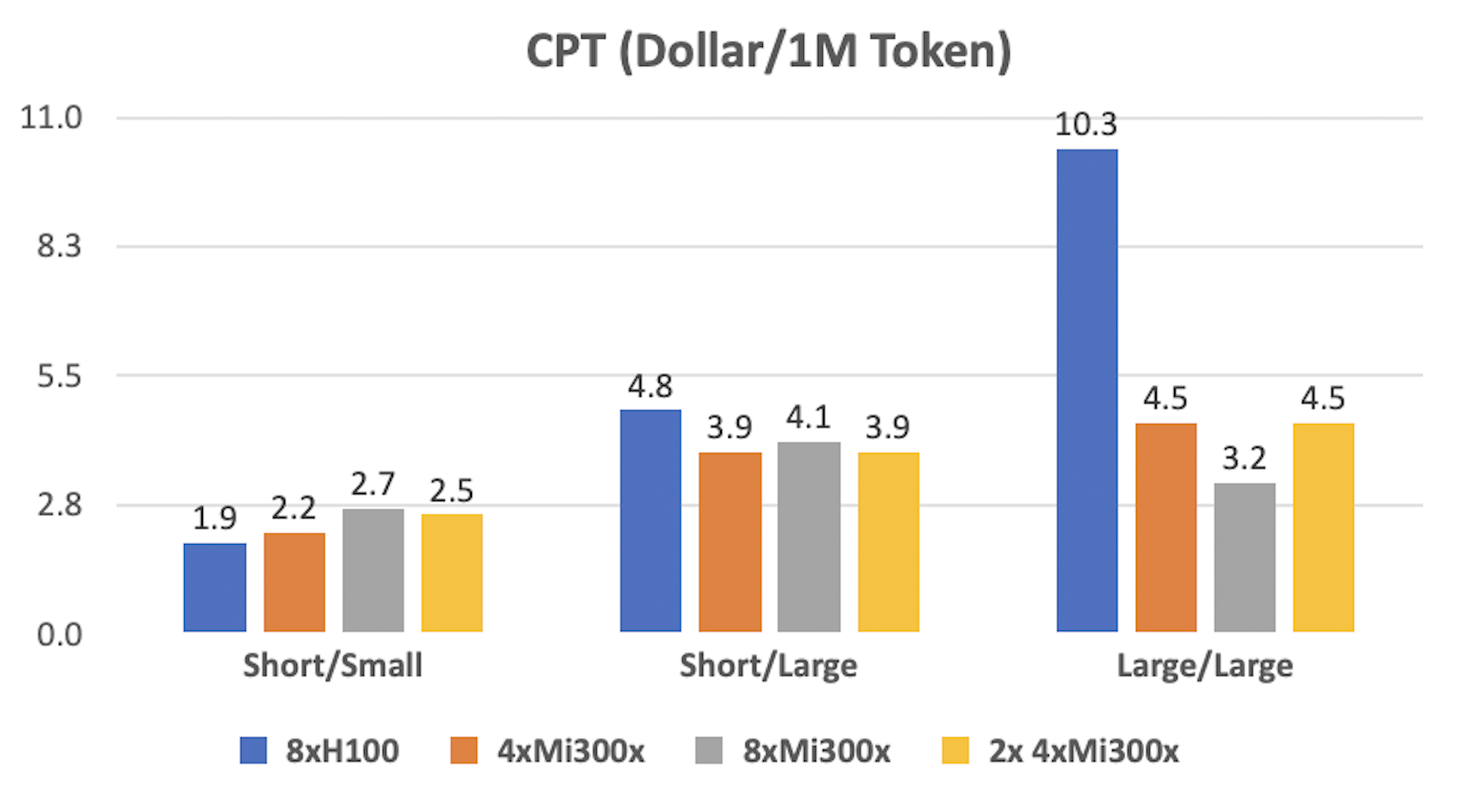
As prompt and batch sizes grow, the NVIDIA H100 reaches memory limits, causing a sharp drop in cost-effectiveness. In contrast, the 1 FP8 8xMI300x configuration is the most cost-efficient for large prompts.
For large prompts, two parallel replicas running on 4xMI300x lose their cost advantage compared to a single replica on 8xMI300x. The latter offers 51% more memory for the KV cache, improving throughput and reducing cost per token.
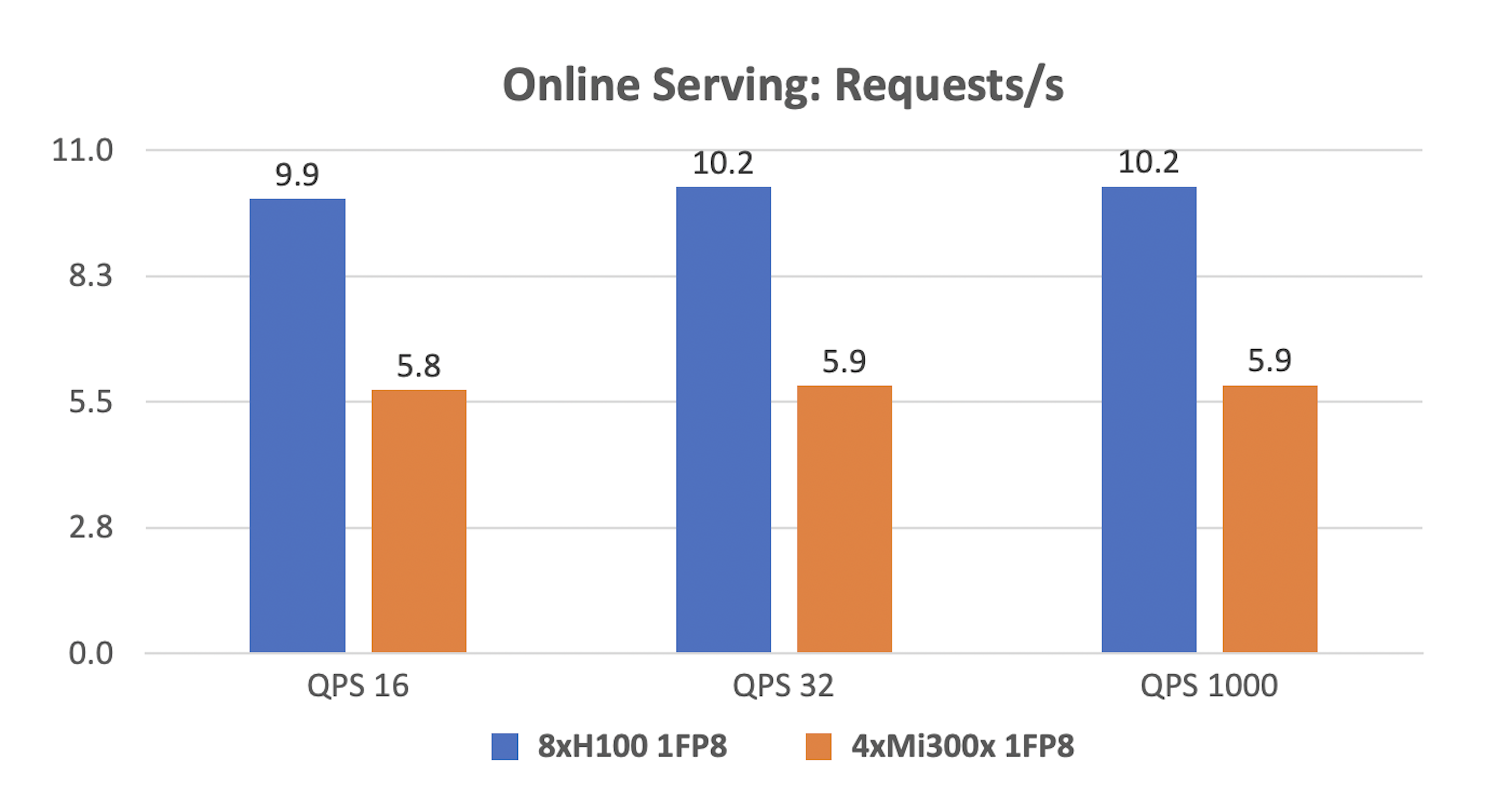
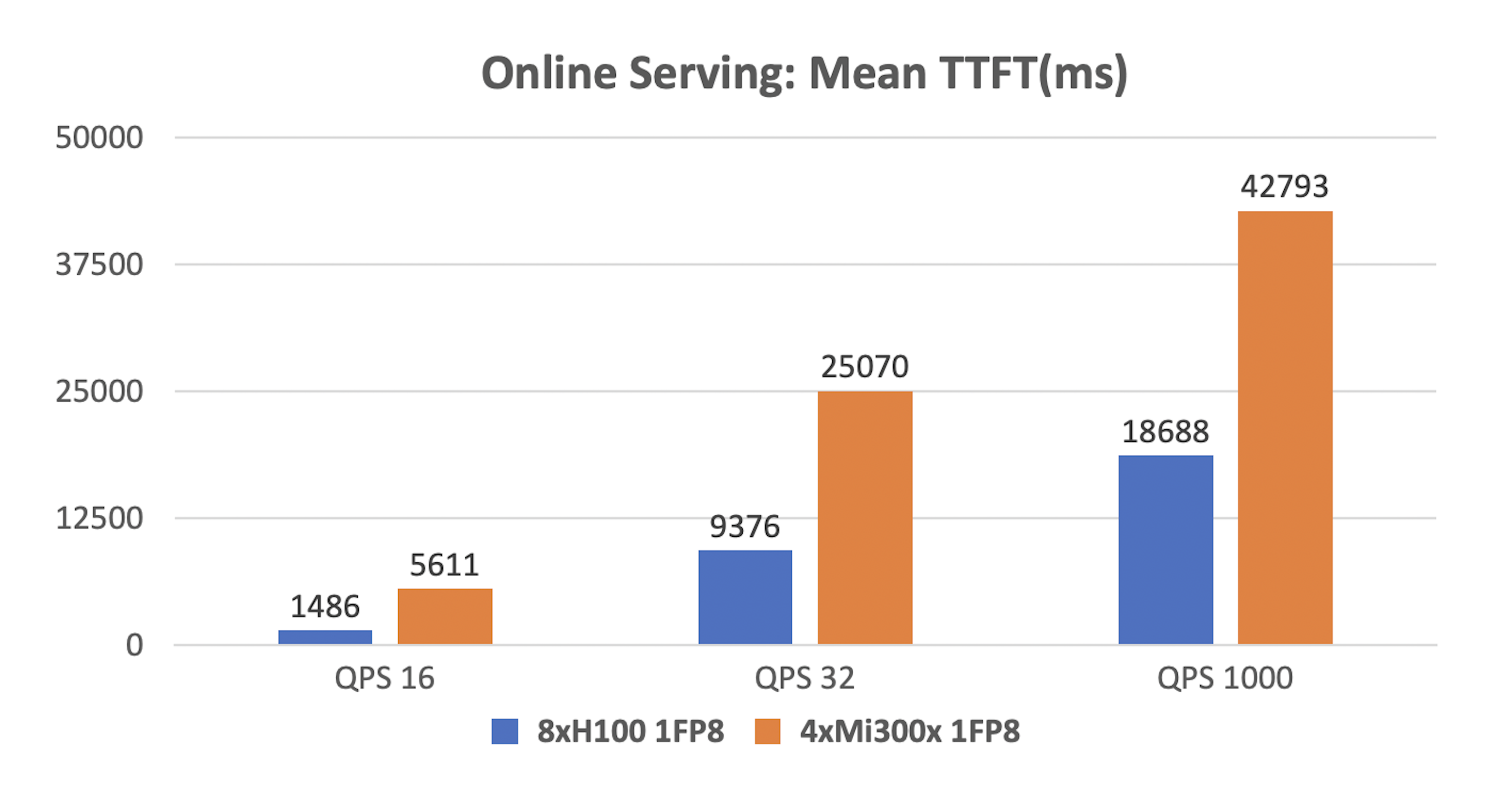
While 4xMI300x is a cost-effective alternative to 8xH100 for smaller load profiles, it underperforms in online serving. 8xH100 SXM5 processes 74% more requests per second and reduces TTFT by at least 50% at all QPS levels.
Throughput¶
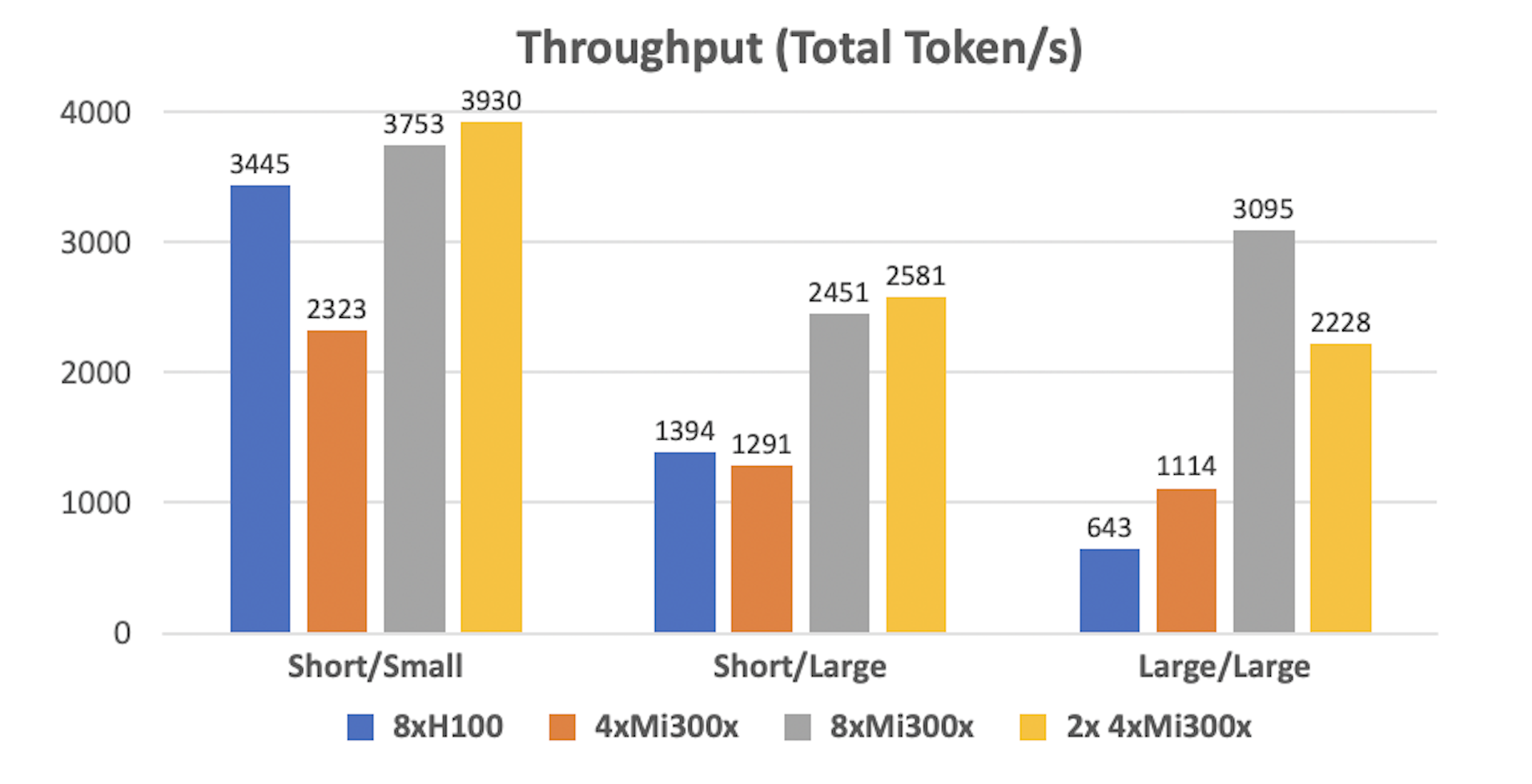
With large prompts and batch sizes, two replicas on 4xMI300x GPUs hit memory saturation when total tokens (prompt length x batch size) exceed the available memory for the KV cache. This forces the inference engine to compute KV tensors on-the-fly or offload them to CPU memory, degrading throughput.
In Lambda’ benchmark, an 8xH200 setup processed 3.4 times more tokens per second than an 8xH100. Extrapolating to our setup, an 8xH200 would process around 2,186 tokens per second (3.4 × 643), though still lower than 8xMI300x.
| AMD MI300x | NVIDIA H200 | |
|---|---|---|
| GPU Memory | 192 GB | 141 GB |
| Memory Type | HBM3 | HBM3e |
| Peak Memory Bandwidth | 5.3TB/s | 4.8TB/s |
| TFLOPS (FP8) | 2610 | 1979 |
Replicas on 4xMi300x¶
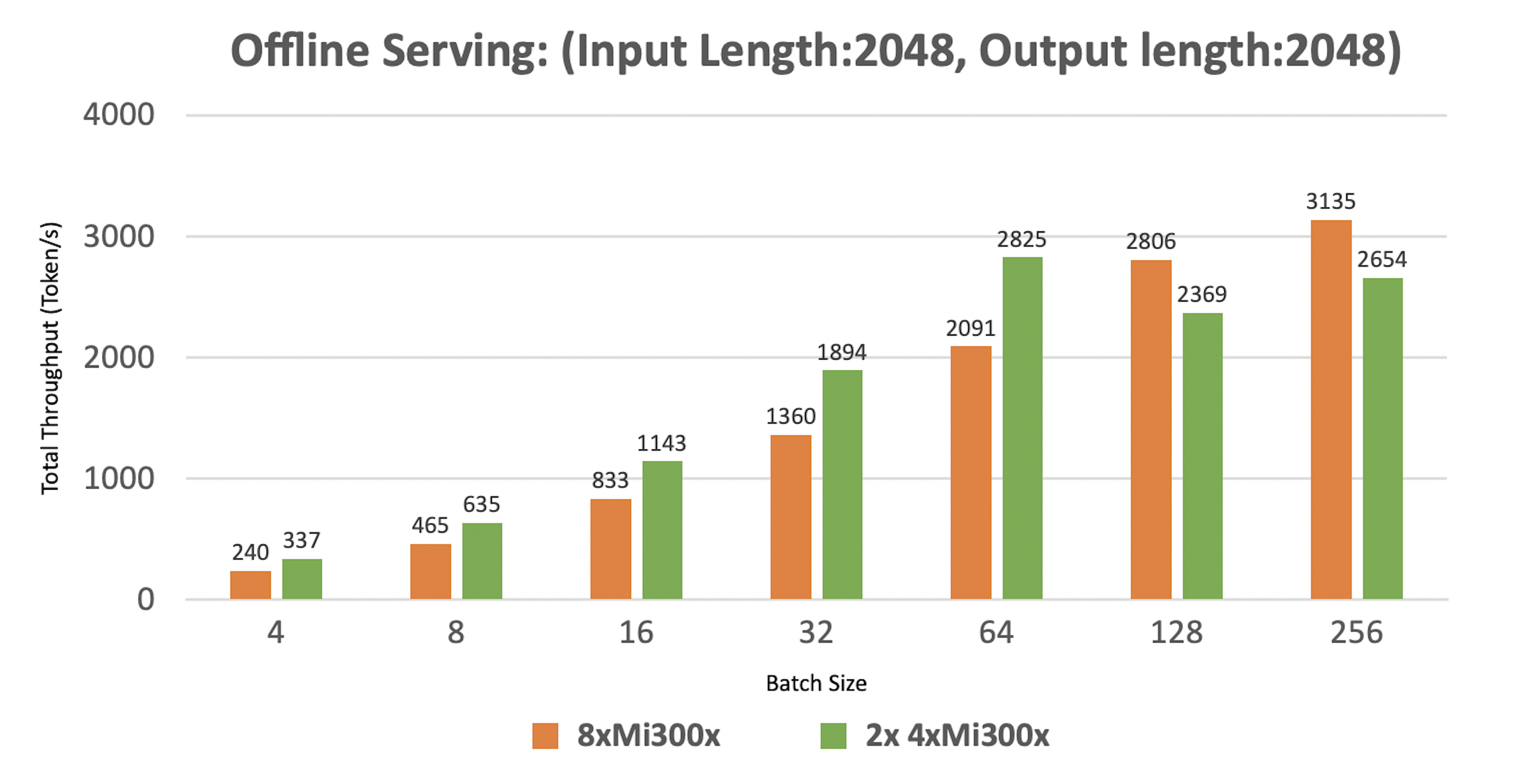
Running two replicas on 4xMI300x delivers better throughput for small to medium prompts than a single replica on 8xMI300x.
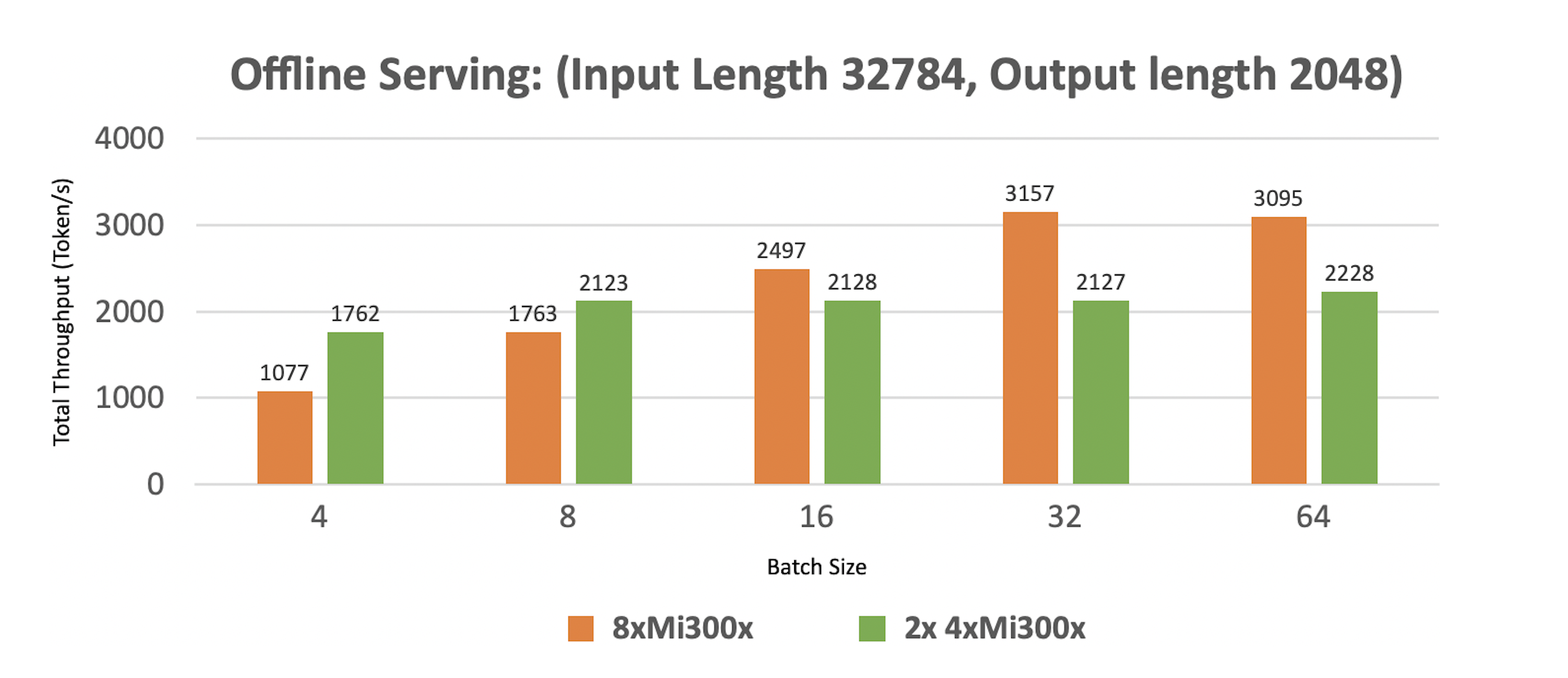
This boost comes from distributing the Llama 3.1 405B model across four GPUs, enabling parallel execution. For small prompts, a single replica underutilizes the GPUs. Running two replicas doubles the batch size, improving GPU utilization and efficiency.
Time To First Token¶
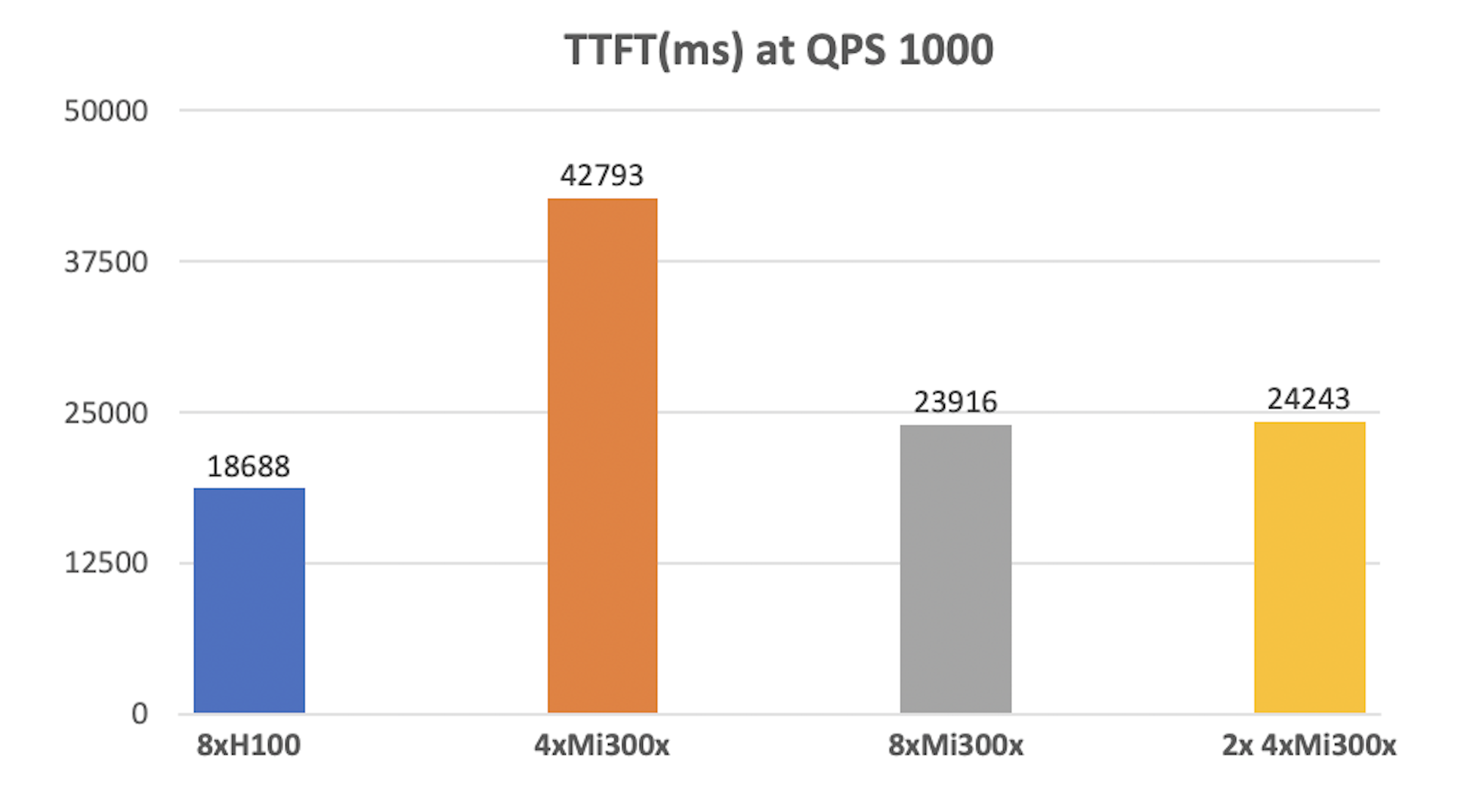
The 4xMI300x setup provides 768 GB of memory (4 GPUs × 192 GB each), compared to 640 GB with 8xH100 (8 GPUs × 80 GB each). However, at 1000 QPS, TTFT for 4xMI300x is over twice as long as for 8xH100
This difference occurs during the prefill stage, where KV tensors for input prompts are computed. Since tensors are processed in parallel, the 8xH100 configuration distributes the load more effectively, reducing computation time.
Despite offering more memory, 4xMI300x lacks the parallelism of 8xH100, leading to longer TTFT.
Time to Serve 1 Request¶
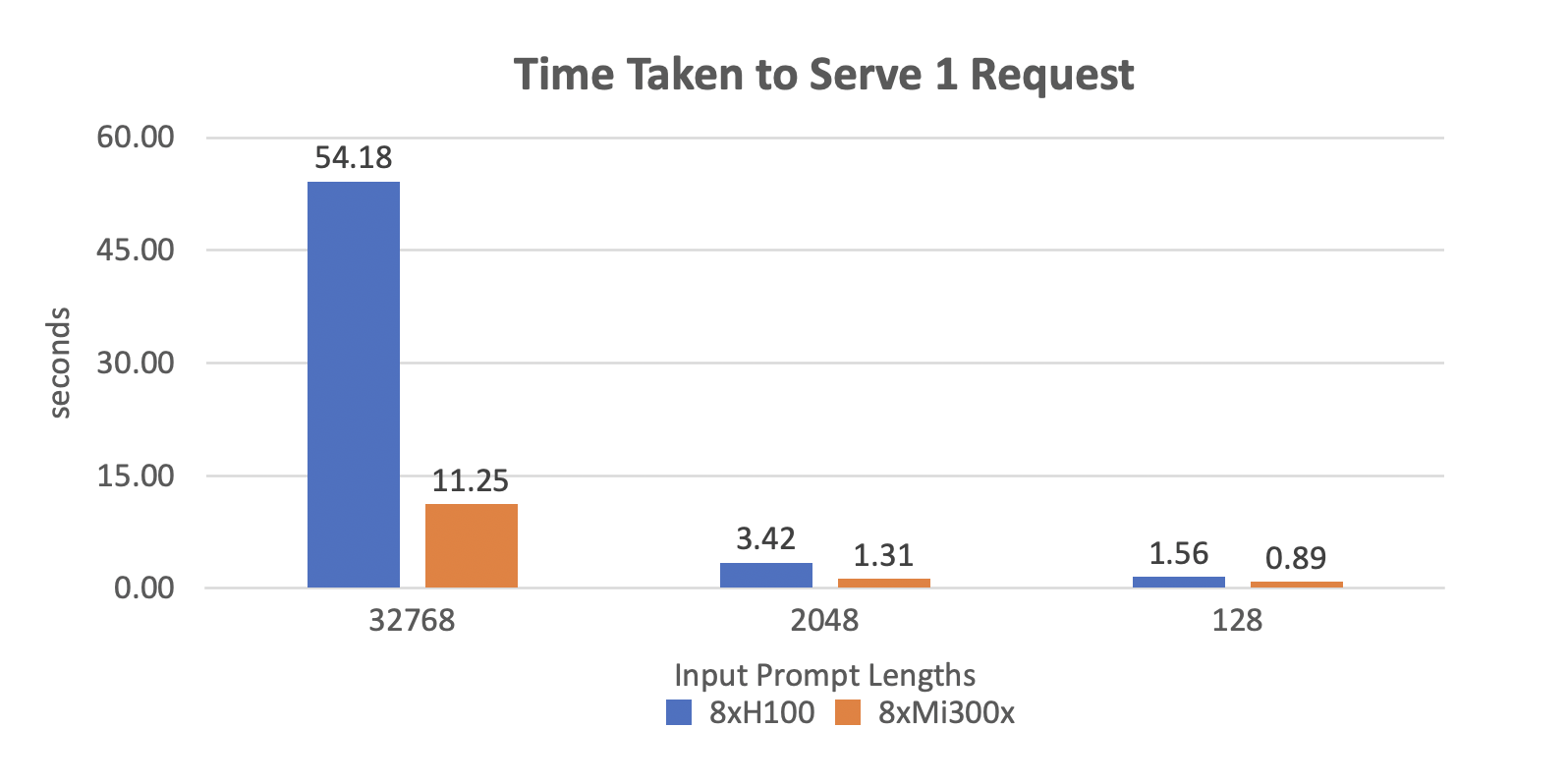
Processing a single large prompt request with 8xMI300x takes around 11.25 seconds. This latency is mainly due to computational demands during the prefill phase, where KV tensors are computed.
Optimizations like automatic prefix caching could help reduce this time, but are outside the scope of this benchmark.
Benchmark notes¶
Benchmark setup¶
The script used in this benchmark was designed for large prompts in offline inference. A different script tailored for online inference would provide more accurate insights.
Batch size¶
We compared throughput at batch size 16 for 8xH100 and batch size 64 for 8xMI300x. The 8xH100 setup begins to struggle with batch size 16 due to memory saturation, resulting in slower generation times.
Model checkpoints¶
For AMD MI300x, we used amd/Llama-3.1-405B-Instruct-FP8-KV
to achieve optimal performance, relying on AMD for quantization.
vLLM configuration¶
To maximize inference results on AMD MI300x, we adjusted specific arguments:
$ VLLM_RPC_TIMEOUT=30000 VLLM_USE_TRITON_FLASH_ATTN=0 vllm serve \
meta-llama/Llama-3.1-405B-FP8 -tp 8 \
--max-seq-len-to-capture 16384 \
--served-model-name meta-llama/Llama-3.1-405B-FP8 \
--enable-chunked-prefill=False \
--num-scheduler-step 15 \
--max-num-seqs 1024
Our benchmark focused on testing inference with tensor parallelism. Integrating tensor and pipeline parallelism could provide additional insights.
On B200, MI325x, and MI350x¶
The MI325x offers 64GB more HBM and 0.7TB/s higher bandwidth than MI300x. However, because it has the same FP8 TFLOPS, it doesn't provide significant compute gains, positioning it against NVIDIA's H200.
The NVIDIA B200 outperforms MI300x and MI325x with more TFLOPS and higher peak memory bandwidth, resulting in lower TTFT by reducing compute time for KV tensors and memory transfer times during the decode stage. We expect the B200 to challenge MI325x, as long as memory saturation is avoided.
Notably, future GPUs from AMD and NVIDIA are expected to support FP4 and FP6, improving throughput, latency, and cost-efficiency.
| AMD MI300x | AMD MI325x | AMD MI350x | NVIDIA B200 | |
|---|---|---|---|---|
| GPU Memory | 192 GB | 256 GB | 288GB | 192 GB |
| Memory Type | HBM3 | HBM3e | HBM3e | |
| Peak Memory Bandwidth | 5.3TB/s | 6TB/s | 8TB/s | |
| TFLOPS (FP8) | 2610 | 2610 | 4500 | |
| Low precision | FP8 | FP8 | FP4, FP6, FP8 | FP4, FP6, FP8 |
Source code¶
All the source code and findings to help you replicate the results are available in our GitHub repo.
Thanks to our friends¶
Hot Aisle¶
Hot Aisle sponsored this benchmark by providing access to 8x MI300x hardware. We’re deeply grateful for their support.
If you're looking for top-tier bare metal compute with AMD GPUs, we highly recommend Hot Aisle. With dstack, accessing
your cluster via SSH is seamless and straightforward.
Lambda¶
Lambda sponsored this benchmark with credits for on-demand 8x H100 instances. We’re truly thankful for their support.
For top-tier cloud compute with NVIDIA GPUs, Lambda is an excellent choice. Once set up, you can easily provision
compute, manage clusters, and orchestrate your AI workloads using dstack.