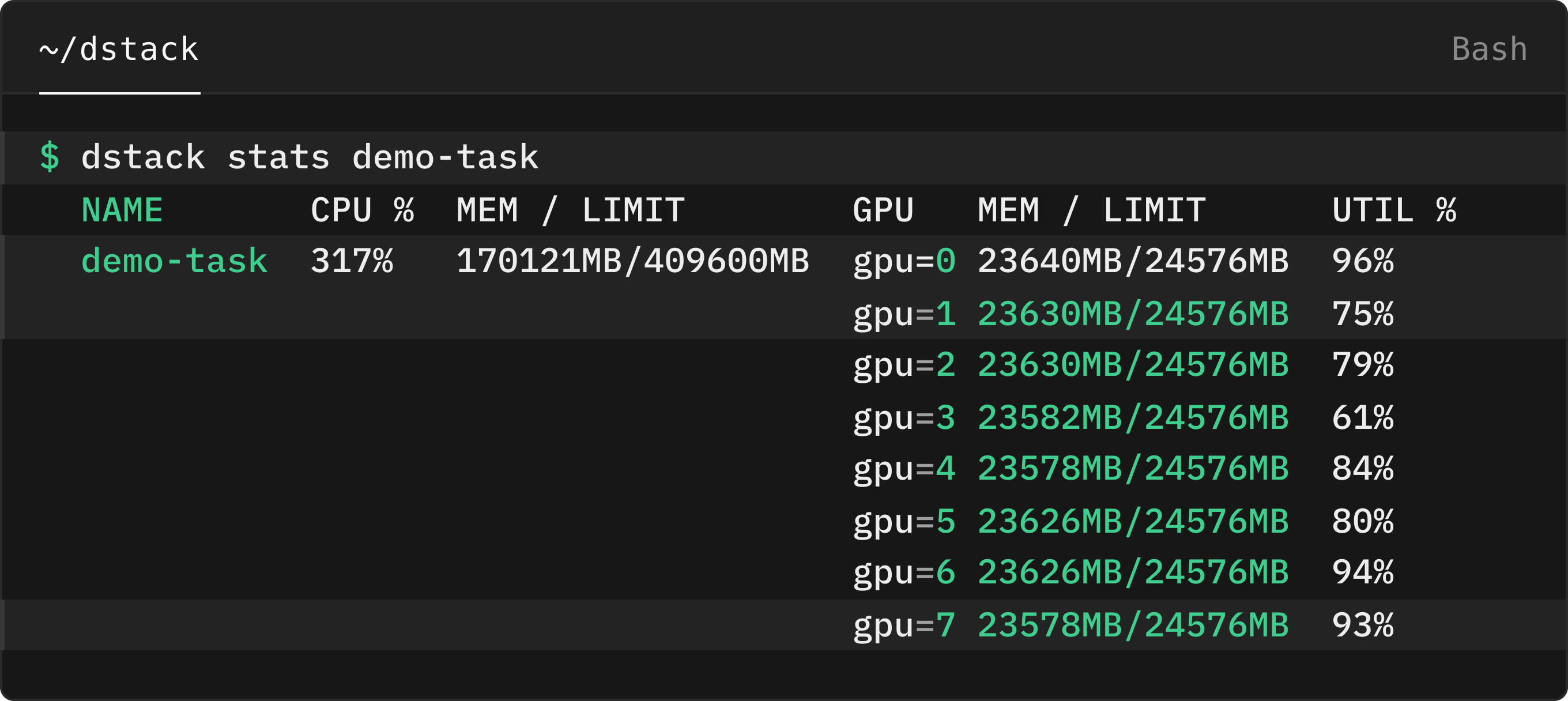
Case study: how EA uses dstack to fast-track AI development
At NVIDIA GTC 2025, Electronic Arts shared how they’re scaling AI development and managing infrastructure across teams. They highlighted using tools like dstack to provision GPUs quickly, flexibly, and cost-efficiently. This case study summarizes key insights from their talk.

EA has over 100+ AI projects running, and the number keeps growing. There are many teams with AI needs—game dev, ML engineers, AI researchers, and platform teams—supported by a central tech team. Some need full MLOps support; others have in-house expertise but need flexible tooling and infrastructure.