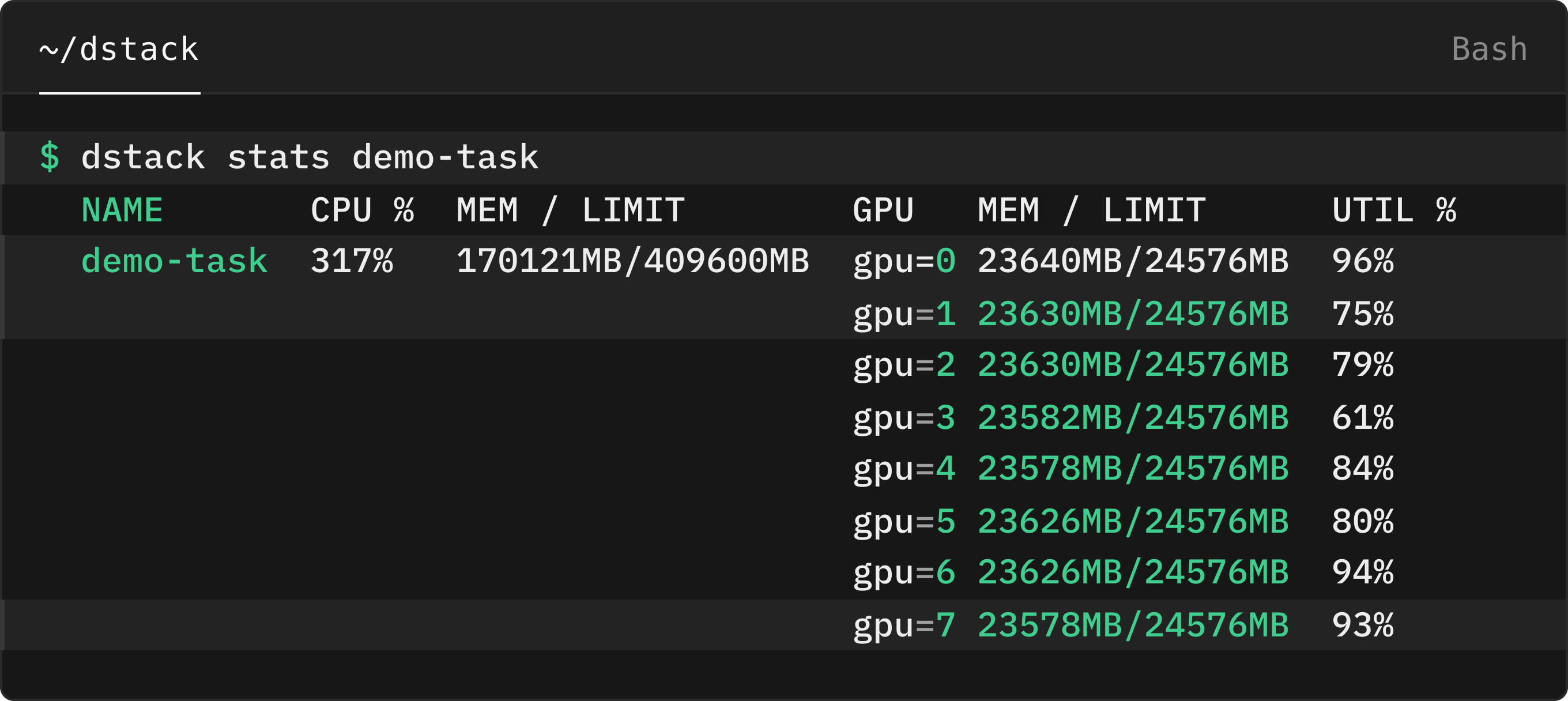
Built-in UI for monitoring essential GPU metrics
AI workloads generate vast amounts of metrics, making it essential to have efficient monitoring tools. While our recent update introduced the ability to export available metrics to Prometheus for maximum flexibility, there are times when users need to quickly access essential metrics without the need to switch to an external tool.

Previously, we introduced a CLI command that allows users to view essential GPU metrics for both NVIDIA
and AMD hardware. Now, with this latest update, we’re excited to announce the addition of a built-in dashboard within
the dstack control plane.