Container orchestration for AI teams
dstack is an open-source container orchestrator that simplifies workload orchestration and drives GPU utilization for ML teams. It works with any GPU cloud, on-prem cluster, or accelerated hardware.
Unified compute layer for AI
dstack redefines the container orchestration layer for AI workloads, tailoring the developer experience for ML teams while keeping it open and vendor-agnostic.
dstack natively integrates with leading GPU clouds and on-prem clusters, regardless of hardware vendor.

Backends
dstack manages instances and clusters via native GPU cloud integration for efficient provisioning with its built-in scheduler. It also runs smoothly on Kubernetes if that fits your environment.
In both cases, dstack acts as an enhanced control plane, making AI compute orchestration more efficient.
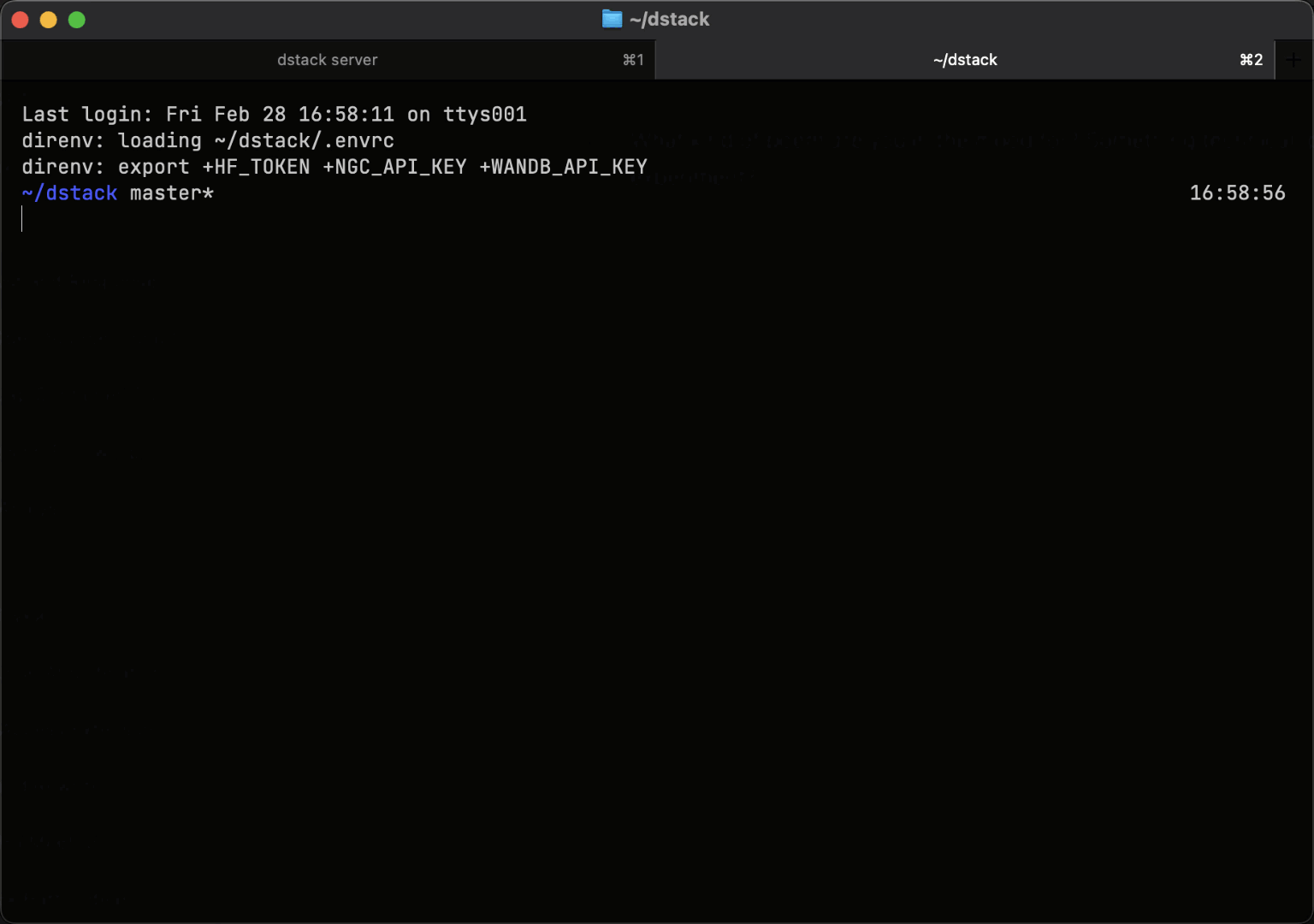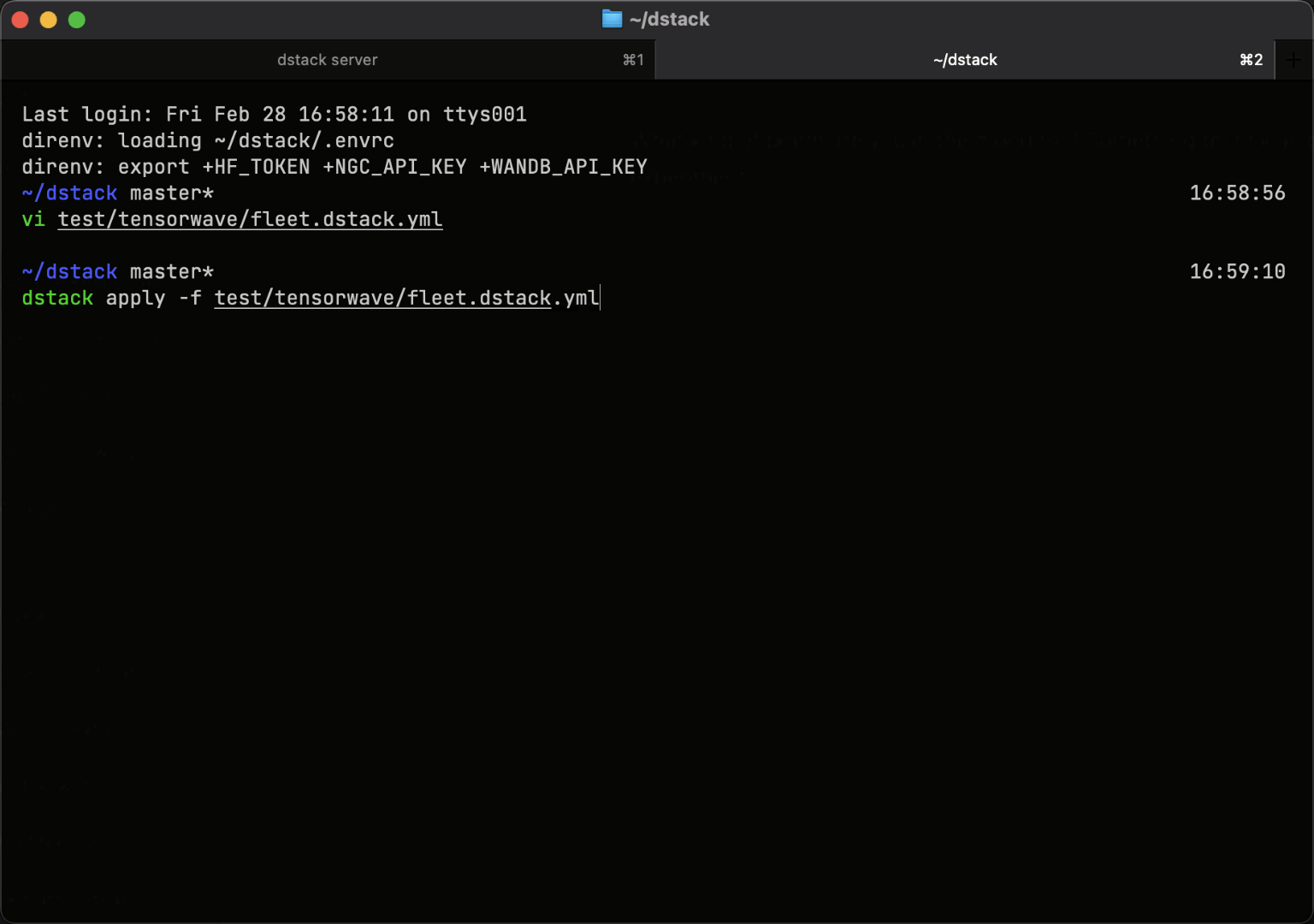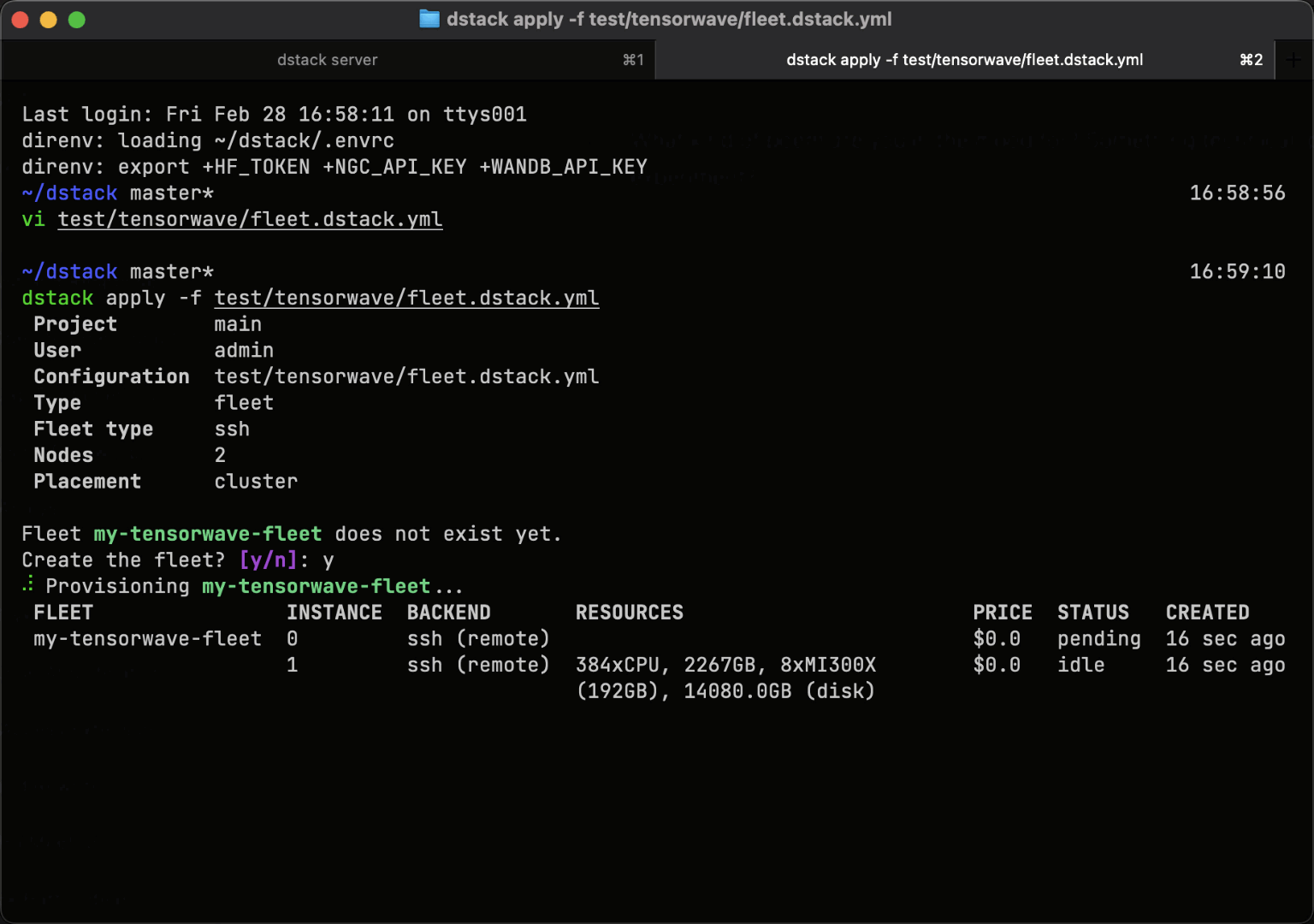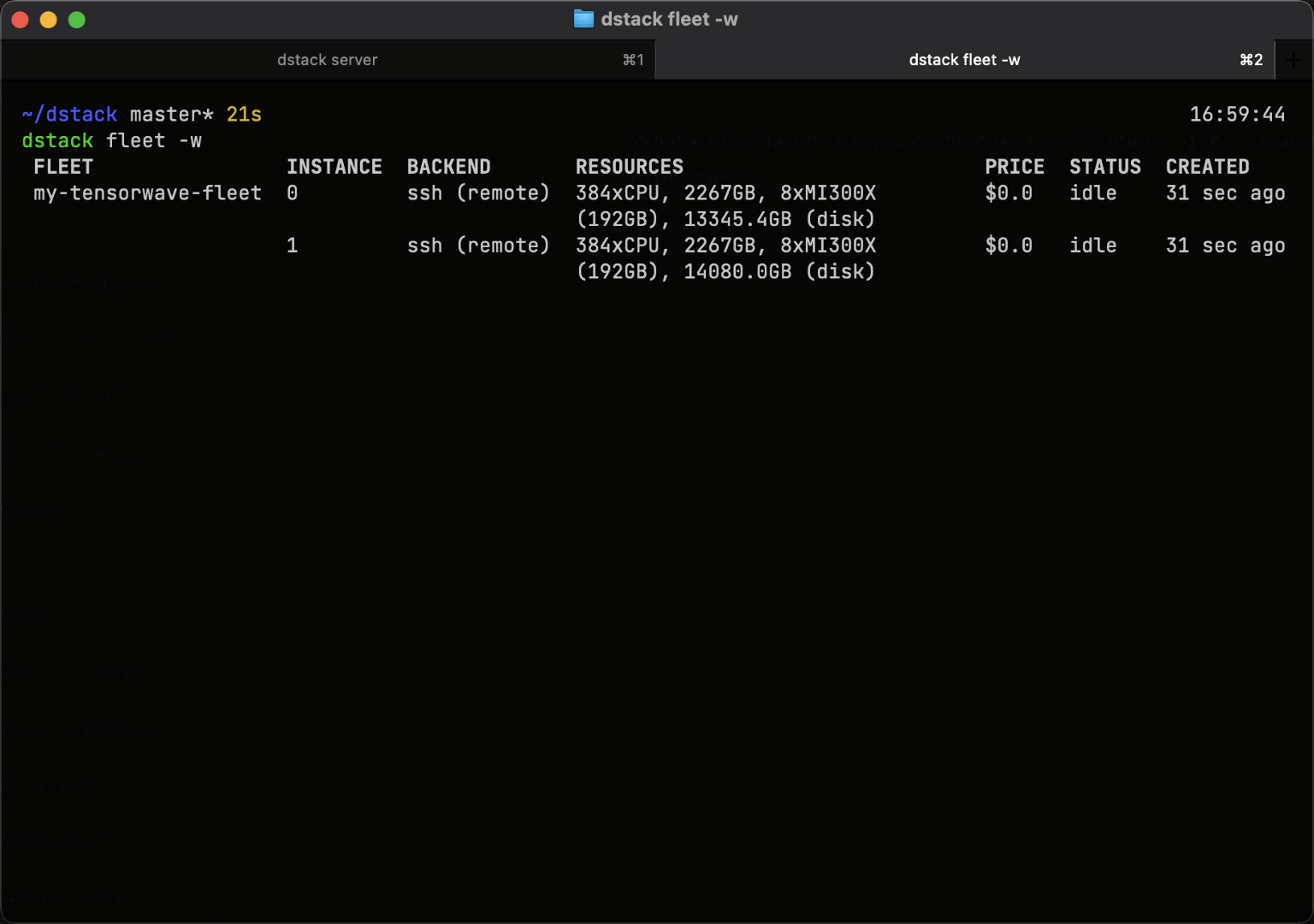
SSH fleets
Bare-metal and manually provisioned clusters can be connected to dstack using SSH fleets.
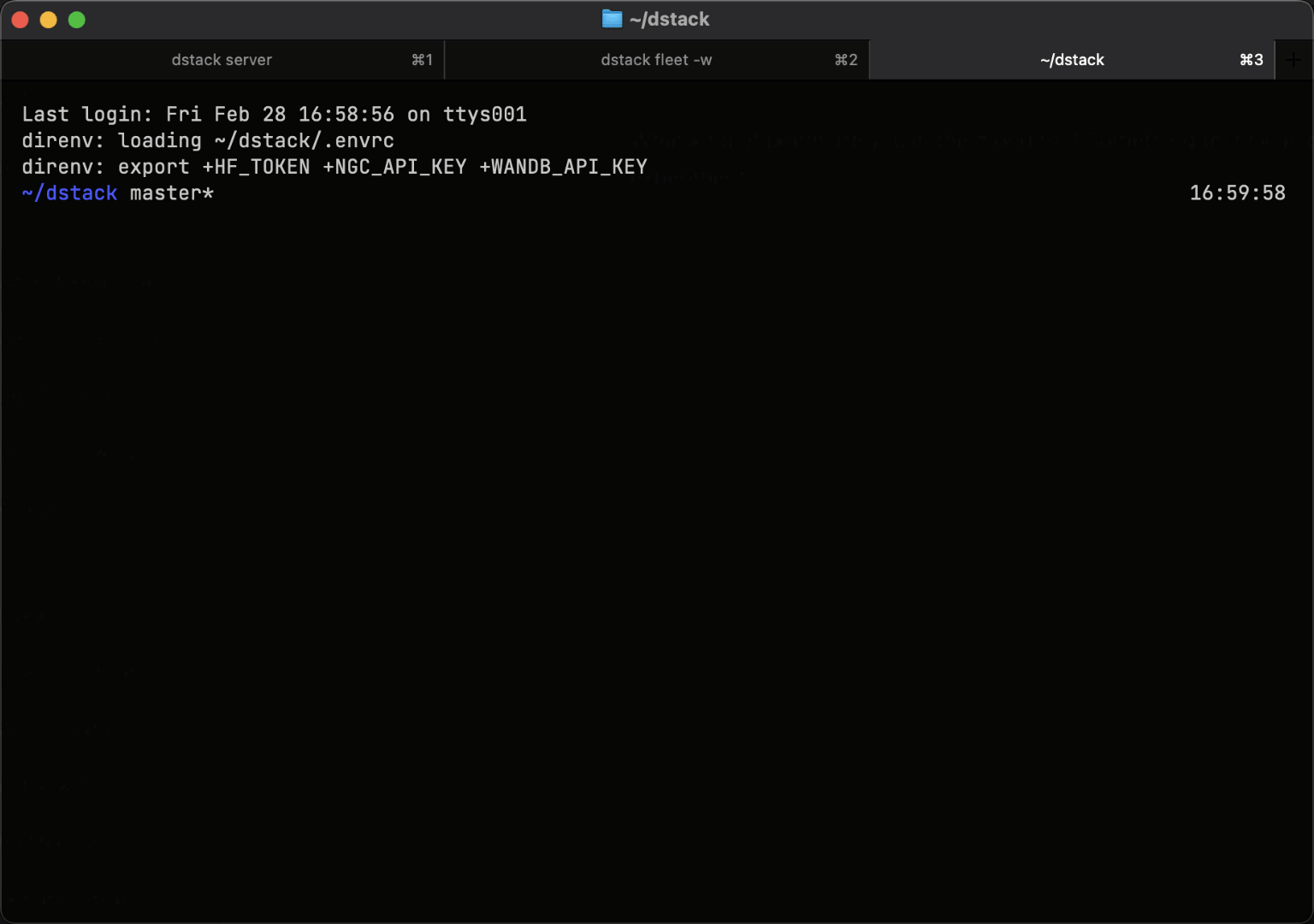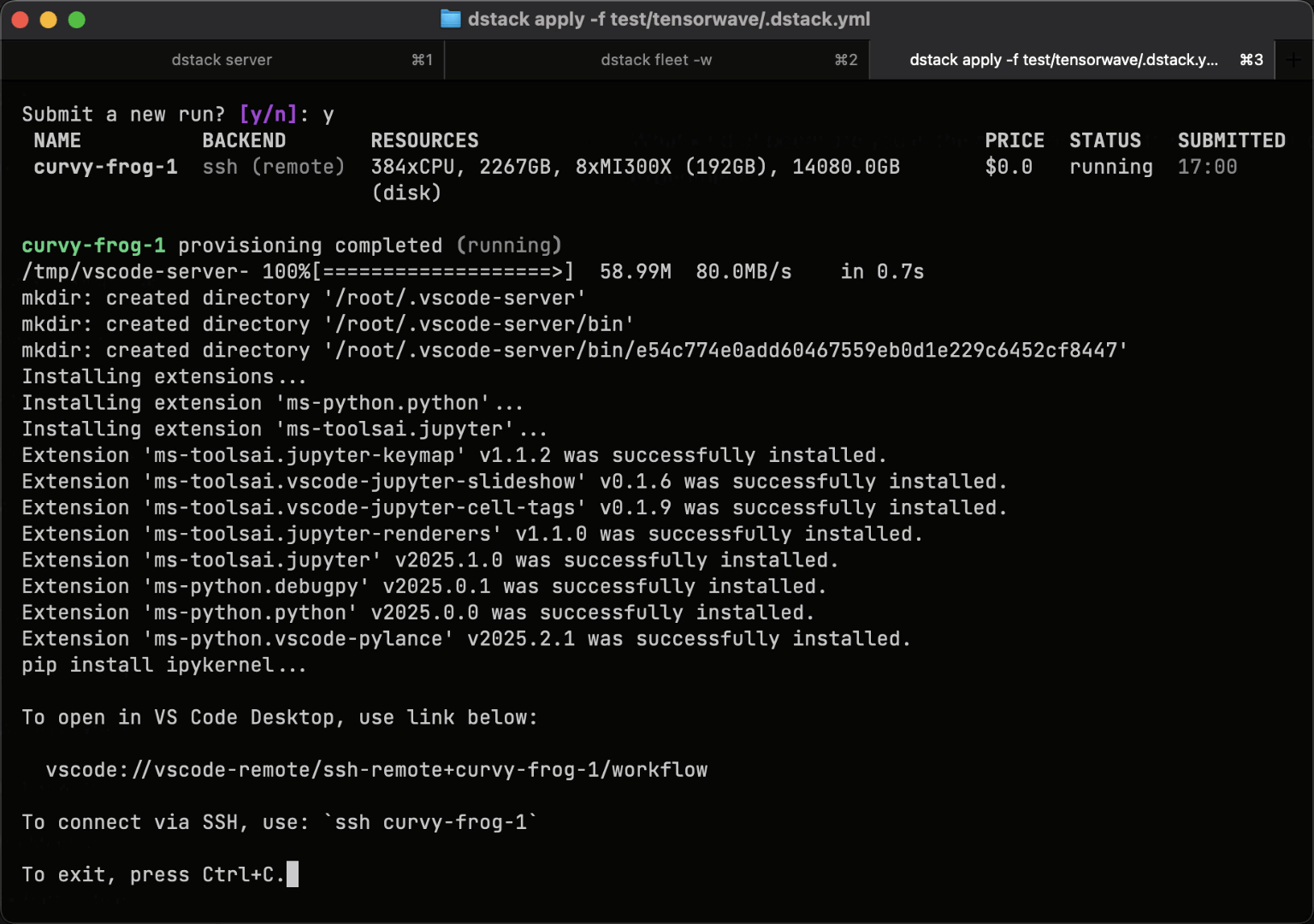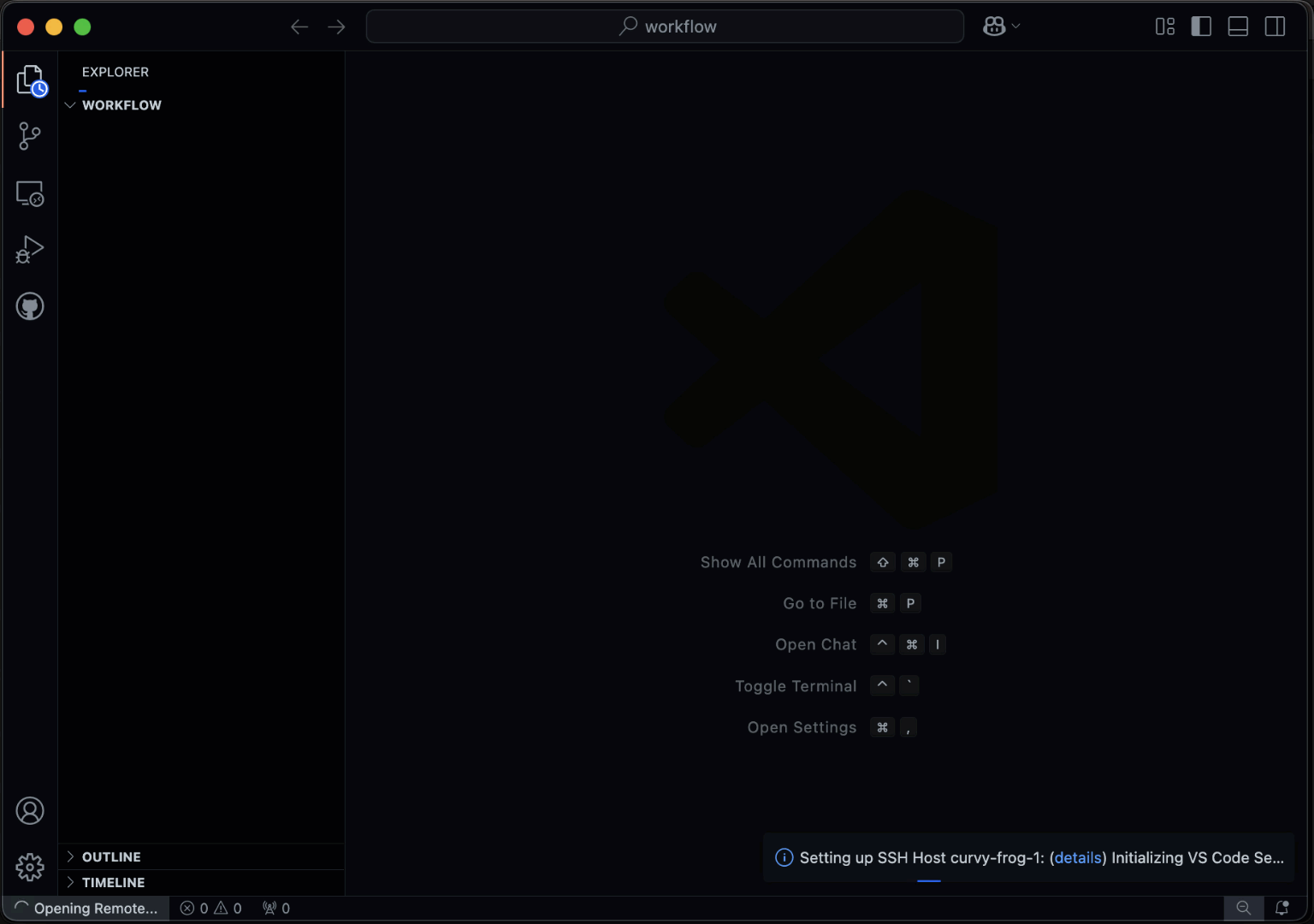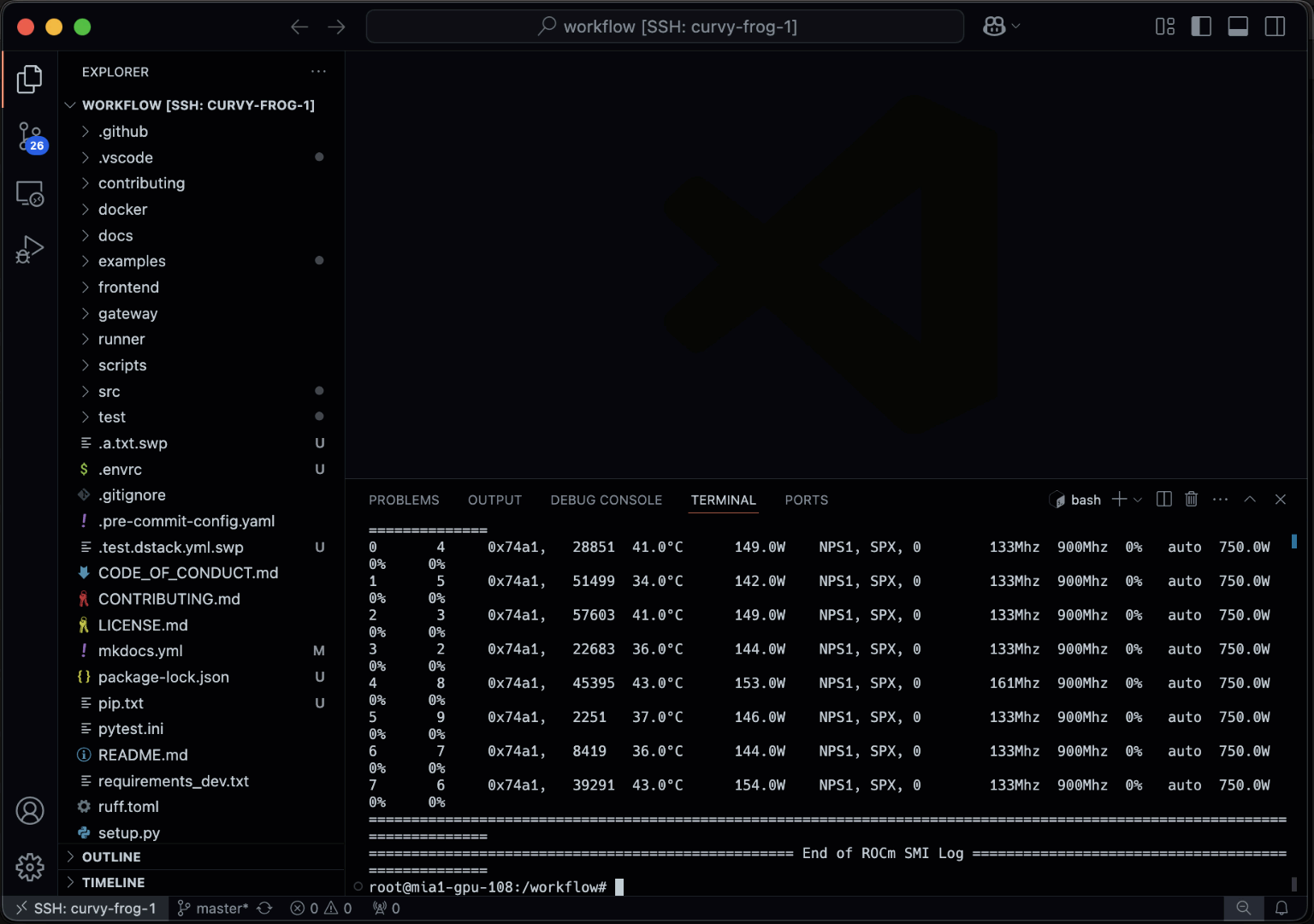
Dev environments
Before running training jobs or deploying model endpoints, ML engineers often experiment with their code in a desktop IDE while using cloud or on-prem GPU machines. Dev environments simplify and streamline this process.
Tasks
Tasks simplify the process of scheduling jobs on either optimized clusters or individual instances. They can be used for pre-training or fine-tuning models, as well as for running any AI or data workloads that require efficient GPU utilization.
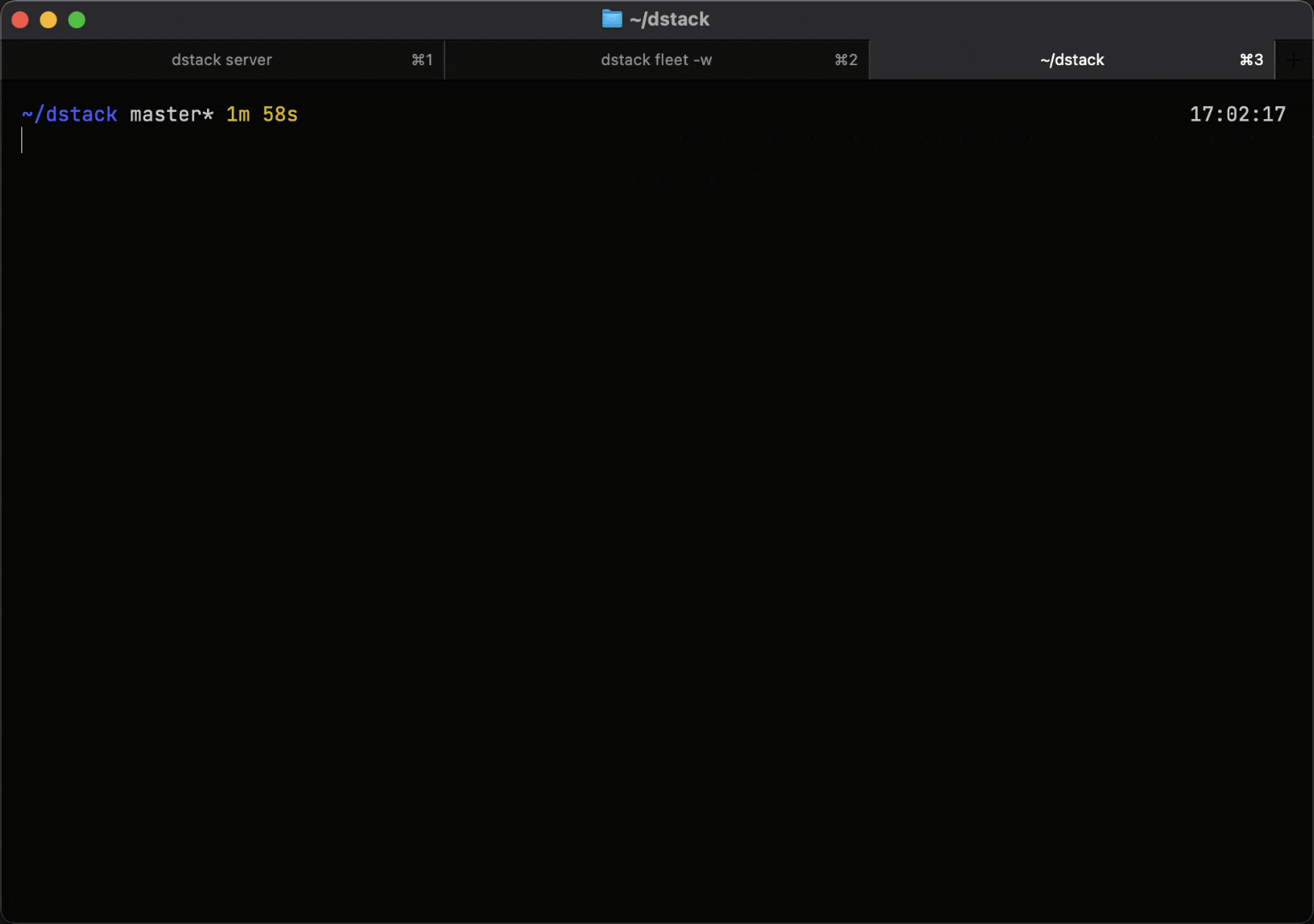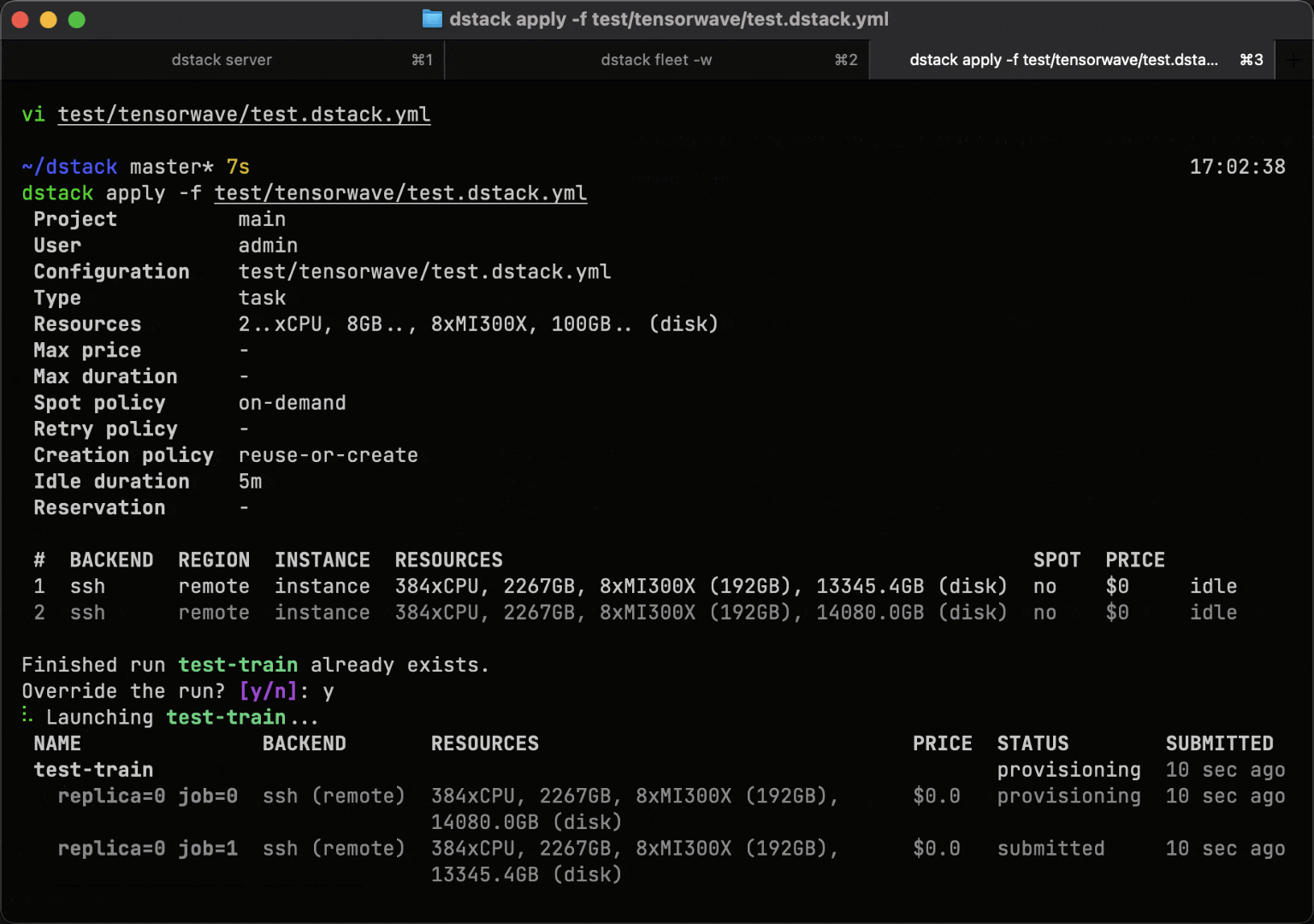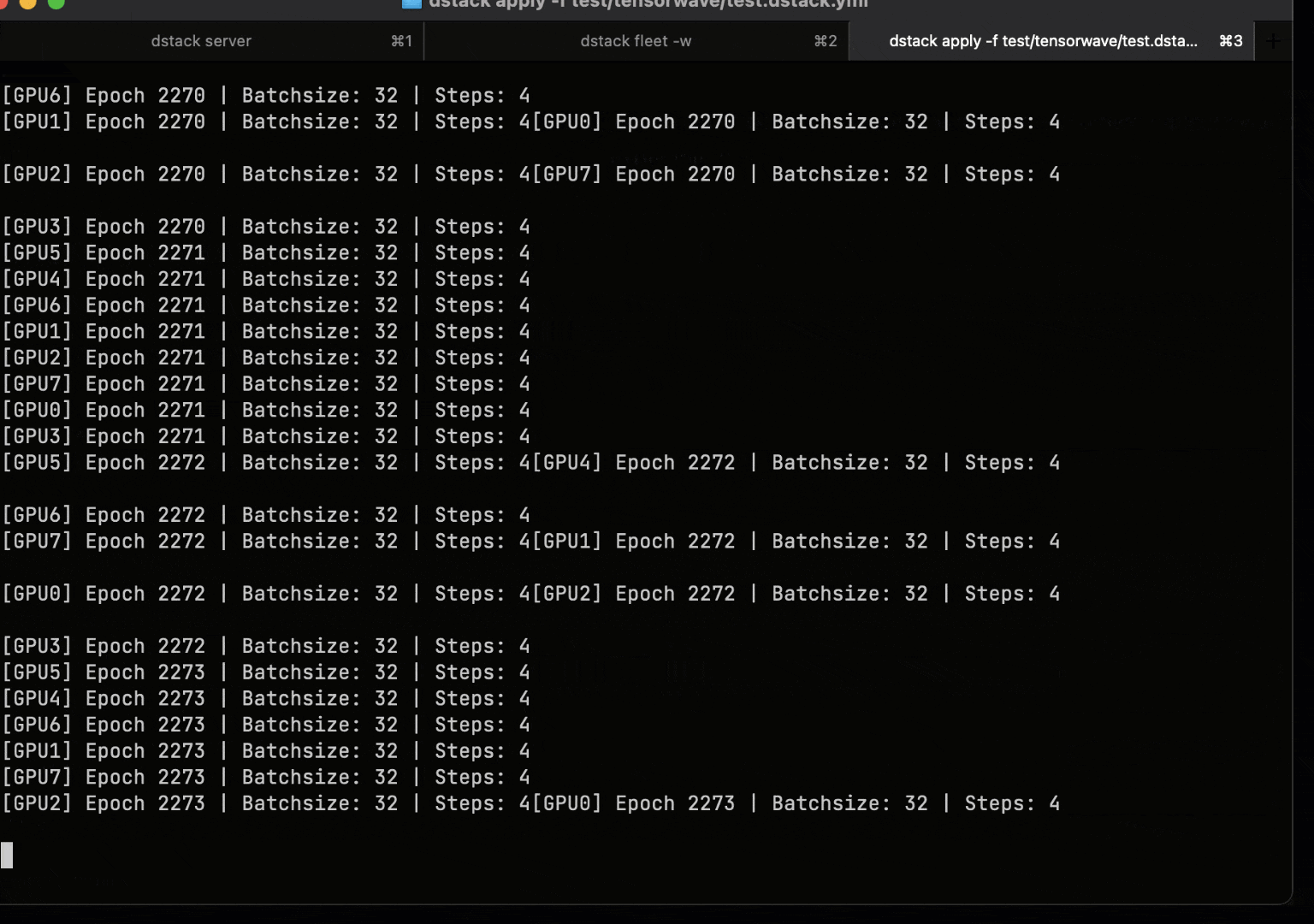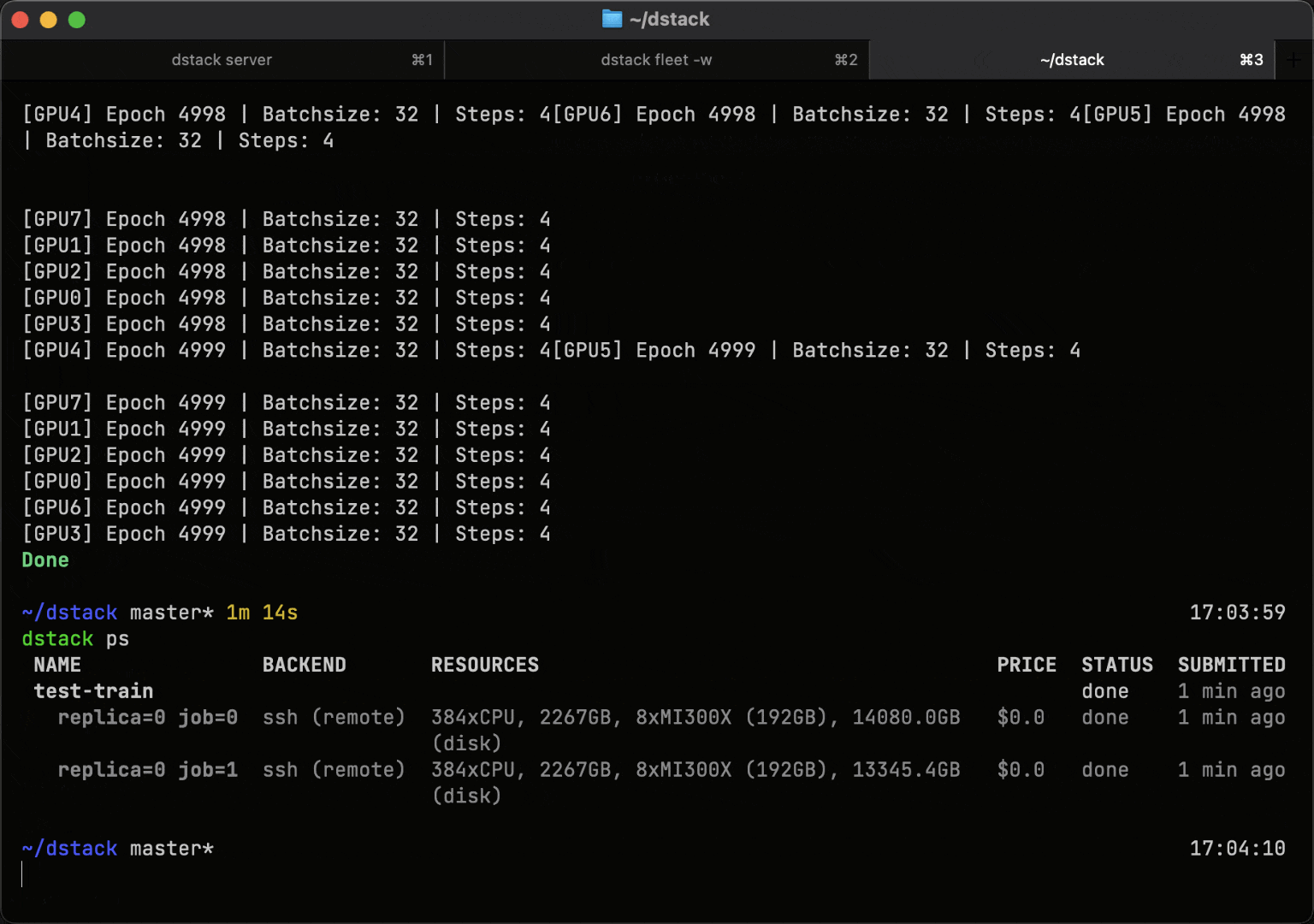
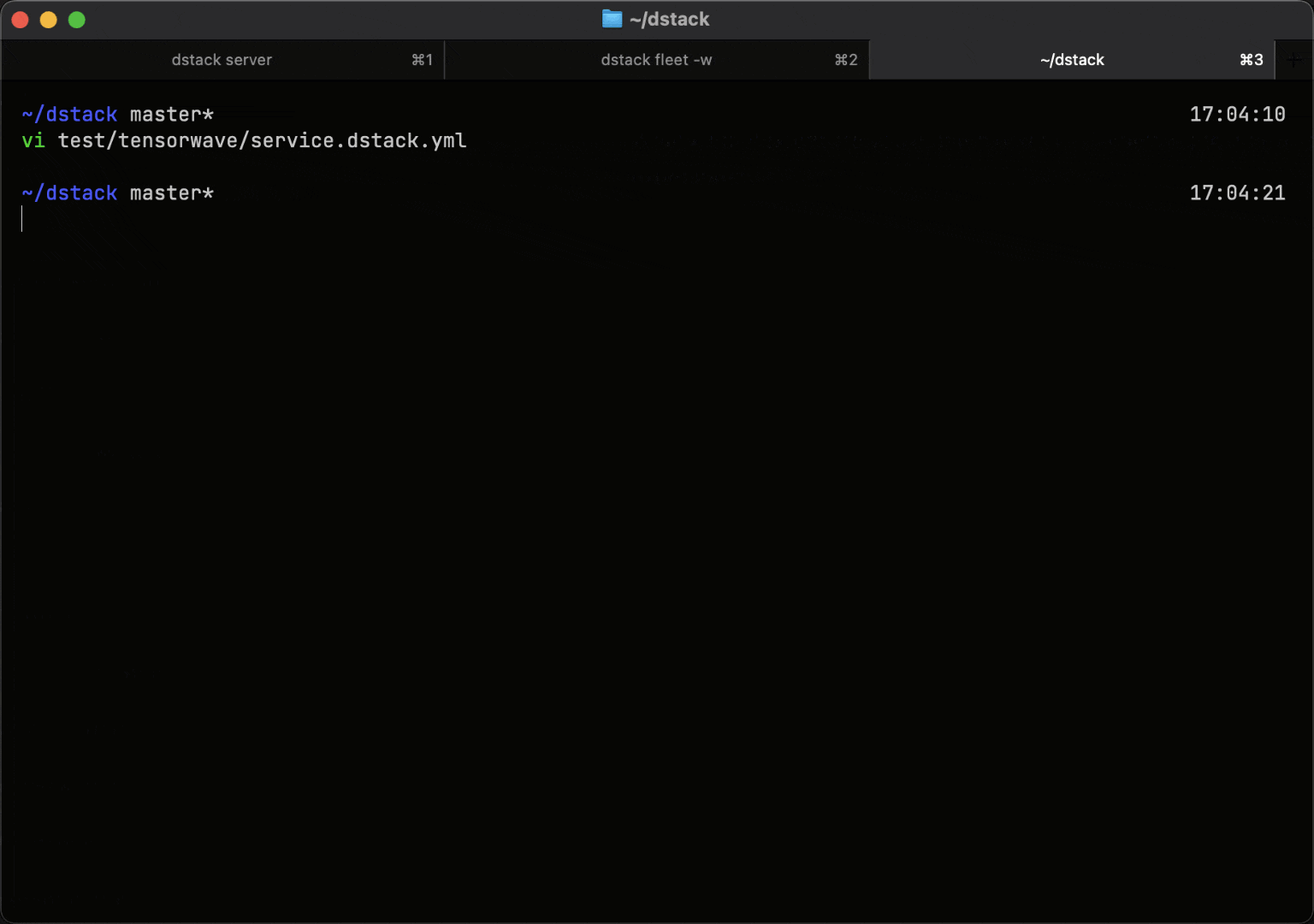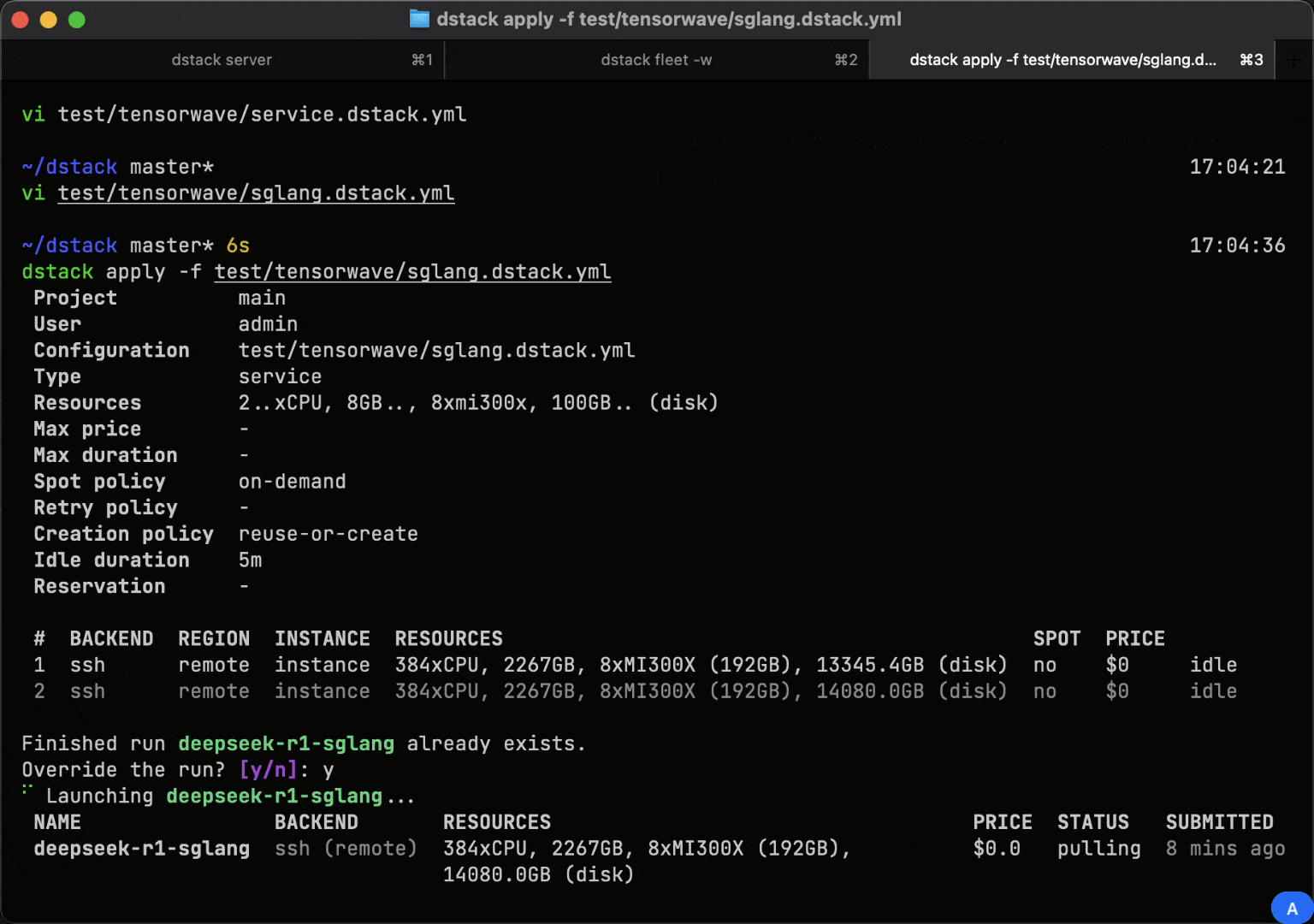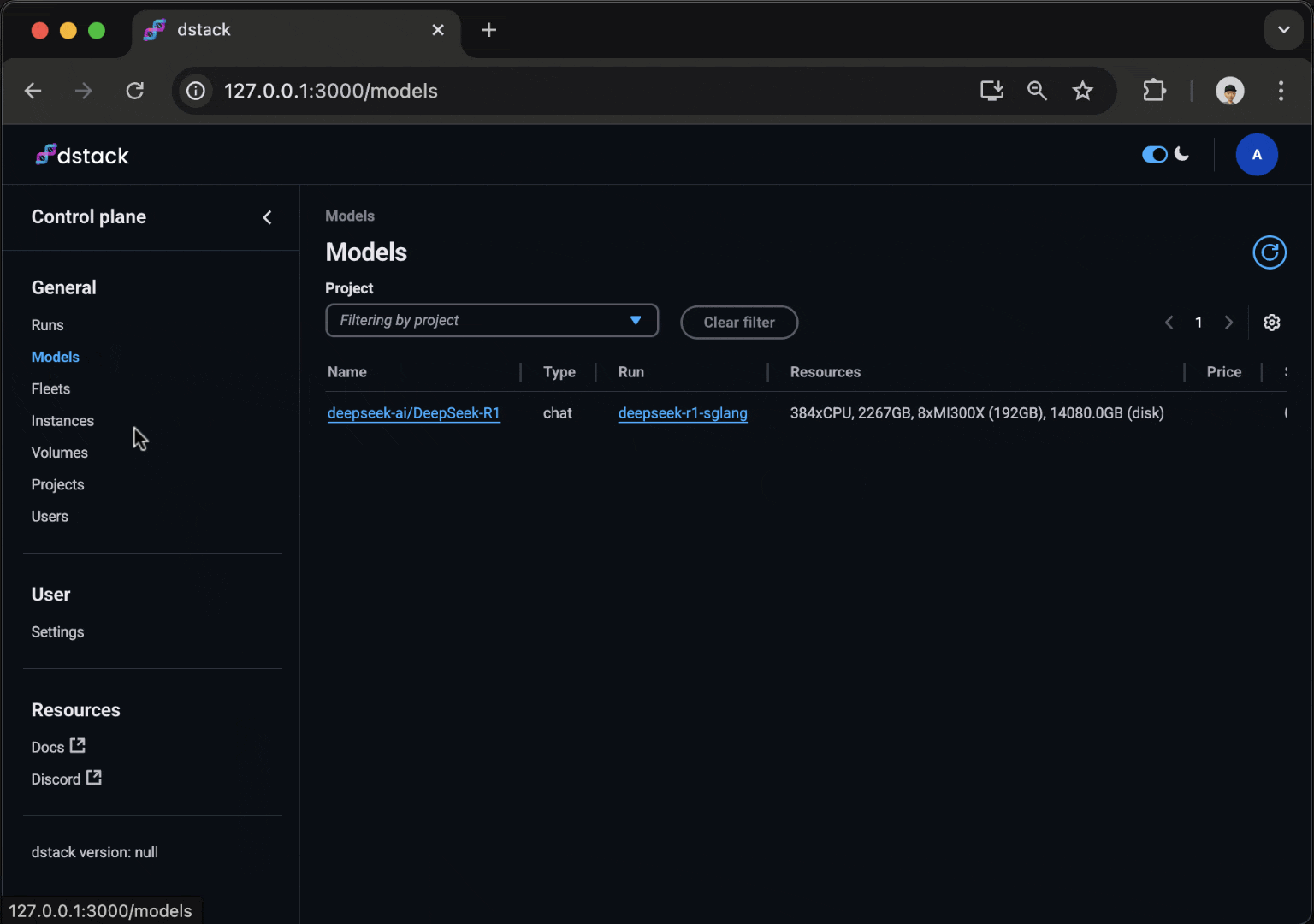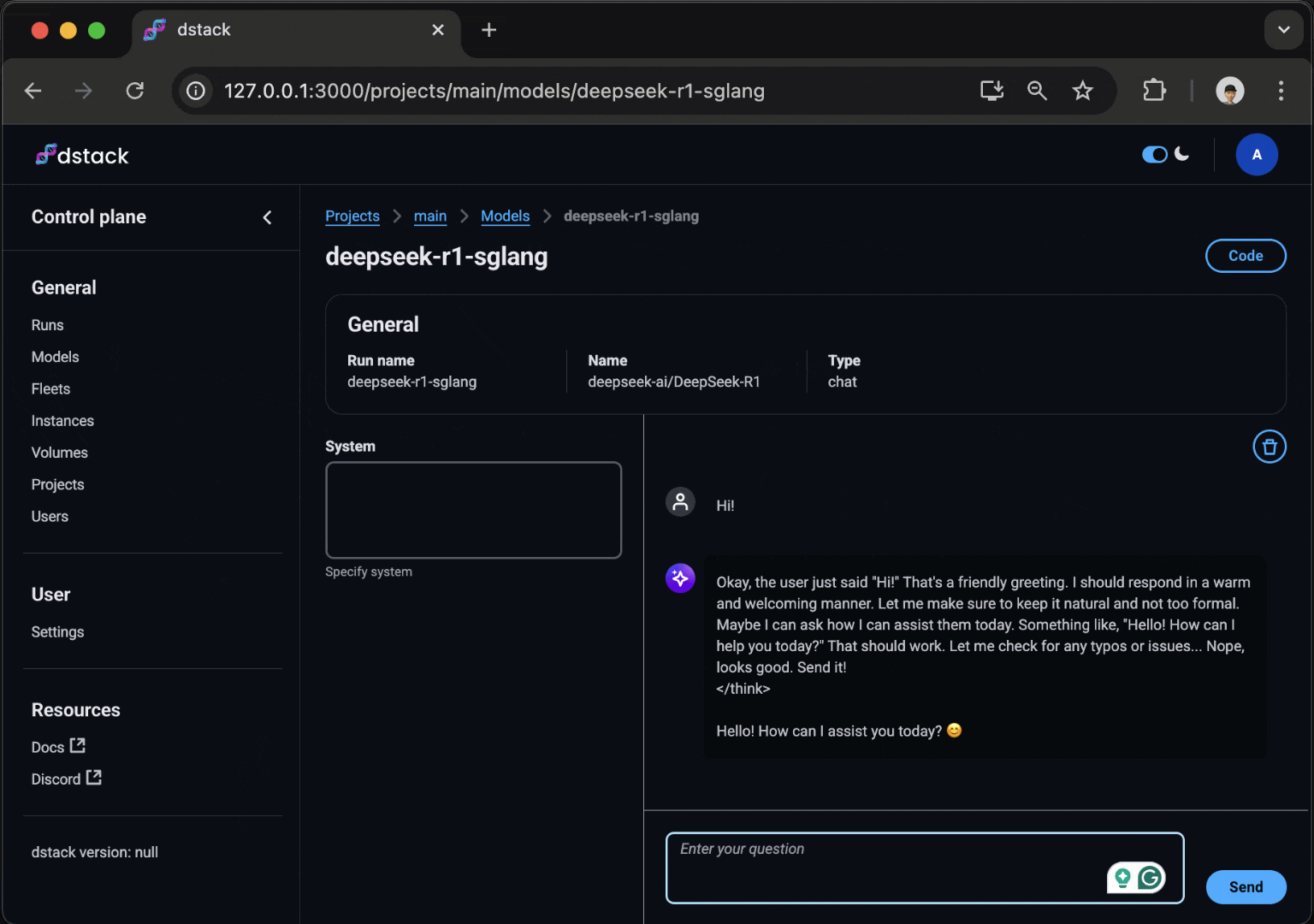
Services
With dstack, you can easily deploy any model as a secure, auto-scaling OpenAI-compatible endpoint, all while using your custom code, Docker image, and serving framework.
Loved by world-class ML teams

Wah Loon Keng
Sr. AI Engineer @Electronic Arts
With dstack, AI researchers at EA can spin up and scale experiments without touching infrastructure. It supports everything from quick prototyping to multi-node training on any cloud.

Aleksandr Movchan
ML Engineer @Mobius Labs
Thanks to dstack, my team can quickly tap into affordable GPUs and streamline our workflows from testing and development to full-scale application deployment.

Alvaro Bartolome
ML Engineer @Argilla
With dstack it's incredibly easy to define a configuration within a repository and run it without worrying about GPU availability. It lets you focus on data and your research.

Park Chansung
ML Researcher @ETRI
Thanks to dstack, I can effortlessly access the top GPU options across different clouds, saving me time and money while pushing my AI work forward.

Eckart Burgwedel
CEO @Uberchord
With dstack, running LLMs on a cloud GPU is as easy as running a local Docker container. It combines the ease of Docker with the auto-scaling capabilities of K8S.

Peter Hill
Co-Founder @CUDO Compute
dstack simplifies infrastructure provisioning and AI development. If your team is on the lookout for an AI platform, I wholeheartedly recommend dstack.
Get started in minutes
Install dstack on your laptop via uv and start it using the CLI, or deploy it anywhere with the dstackai/dstack Docker image.
Set up backends or SSH fleets, then add your team.
FAQ
Kubernetes is a widely used container orchestrator designed for general-purpose deployments. To efficiently support GPU workloads, Kubernetes typically requires custom operators, and it may not offer the most intuitive interface for ML engineers.
dstack takes a different approach, focusing on container orchestration specifically for AI workloads, with the goal of making life easier for ML engineers.
Designed to be lightweight, dstack provides a simpler, more intuitive interface for development, training, and inference. It also enables more flexible and cost-effective provisioning and management of clusters.
For optimal flexibility, dstack and Kubernetes can complement each other: dstack can handle development, while Kubernetes manages production deployments.
Slurm excels at job scheduling across pre-configured clusters.
dstack goes beyond scheduling, providing a full suite of features tailored to ML teams, including cluster management, dynamic compute provisioning, development environments, and advanced monitoring. This makes dstack a more comprehensive solution for AI workloads, whether in the cloud or on-prem.
dstack is designed for ML teams aiming to speed up development while reducing GPU costs across top cloud providers or on-prem clusters.
Seamlessly integrated with Git, dstack works with any open-source or proprietary frameworks, making it developer-friendly and vendor-agnostic for training and deploying AI models.
For ML teams seeking a more streamlined, AI-native development platform, dstack provides an alternative to Kubernetes and Slurm, removing the need for MLOps or custom solutions.
Have questions, or need help?
Discord
Talk to us
dstack Enterprise
Looking for a self-hosted dstack with SSO, governance controls, and enterprise support?
dstack Sky
Don't want to host the dstack server or want to get the cheapest GPUs from the marketplace?