Using TPUs for fine-tuning and deploying LLMs¶
If you’re using or planning to use TPUs with Google Cloud, you can now do so via dstack. Just specify the TPU version and the number of cores
(separated by a dash), in the gpu property under resources.
Read below to find out how to use TPUs with dstack for fine-tuning and deploying
LLMs, leveraging open-source tools like Hugging Face’s
Optimum TPU
and vLLM.
Below is an example of a dev environment:
type: dev-environment
name: vscode-tpu
python: 3.11
ide: vscode
resources:
gpu: v2-8
If you've configured the gcp backend, dstack will automatically provision the dev environment with a TPU.
Currently, maximum 8 TPU cores can be specified, so the maximum supported values are
v2-8,v3-8,v4-8,v5litepod-8, andv5e-8. Multi-host TPU support, allowing for larger numbers of cores, is coming soon.
Deployment¶
You can use any serving framework, such as vLLM, TGI. Here's an example of a service that deploys Llama 3.1 8B using Optimum TPU and vLLM.
type: service
name: llama31-service-optimum-tpu
image: dstackai/optimum-tpu:llama31
env:
- HF_TOKEN
- MODEL_ID=meta-llama/Meta-Llama-3.1-8B-Instruct
- MAX_TOTAL_TOKENS=4096
- MAX_BATCH_PREFILL_TOKENS=4095
commands:
- text-generation-launcher --port 8000
port: 8000
# Register the model
model:
format: tgi
type: chat
name: meta-llama/Meta-Llama-3.1-8B-Instruct
# Uncomment to leverage spot instances
#spot_policy: auto
resources:
gpu: v5litepod-4
Once the pull request is merged,
the official Docker image can be used instead of dstackai/optimum-tpu:llama31.
type: service
name: llama31-service-vllm-tpu
env:
- MODEL_ID=meta-llama/Meta-Llama-3.1-8B-Instruct
- HF_TOKEN
- DATE=20240828
- TORCH_VERSION=2.5.0
- VLLM_TARGET_DEVICE=tpu
- MAX_MODEL_LEN=4096
commands:
- pip install https://storage.googleapis.com/pytorch-xla-releases/wheels/tpuvm/torch-${TORCH_VERSION}.dev${DATE}-cp311-cp311-linux_x86_64.whl
- pip3 install https://storage.googleapis.com/pytorch-xla-releases/wheels/tpuvm/torch_xla-${TORCH_VERSION}.dev${DATE}-cp311-cp311-linux_x86_64.whl
- pip install torch_xla[tpu] -f https://storage.googleapis.com/libtpu-releases/index.html
- pip install torch_xla[pallas] -f https://storage.googleapis.com/jax-releases/jax_nightly_releases.html -f https://storage.googleapis.com/jax-releases/jaxlib_nightly_releases.html
- git clone https://github.com/vllm-project/vllm.git
- cd vllm
- pip install -r requirements-tpu.txt
- apt-get install -y libopenblas-base libopenmpi-dev libomp-dev
- python setup.py develop
- vllm serve $MODEL_ID
--tensor-parallel-size 4
--max-model-len $MAX_MODEL_LEN
--port 8000
port: 8000
# Register the model
model: meta-llama/Meta-Llama-3.1-8B-Instruct
# Uncomment to leverage spot instances
#spot_policy: auto
resources:
gpu: v5litepod-4
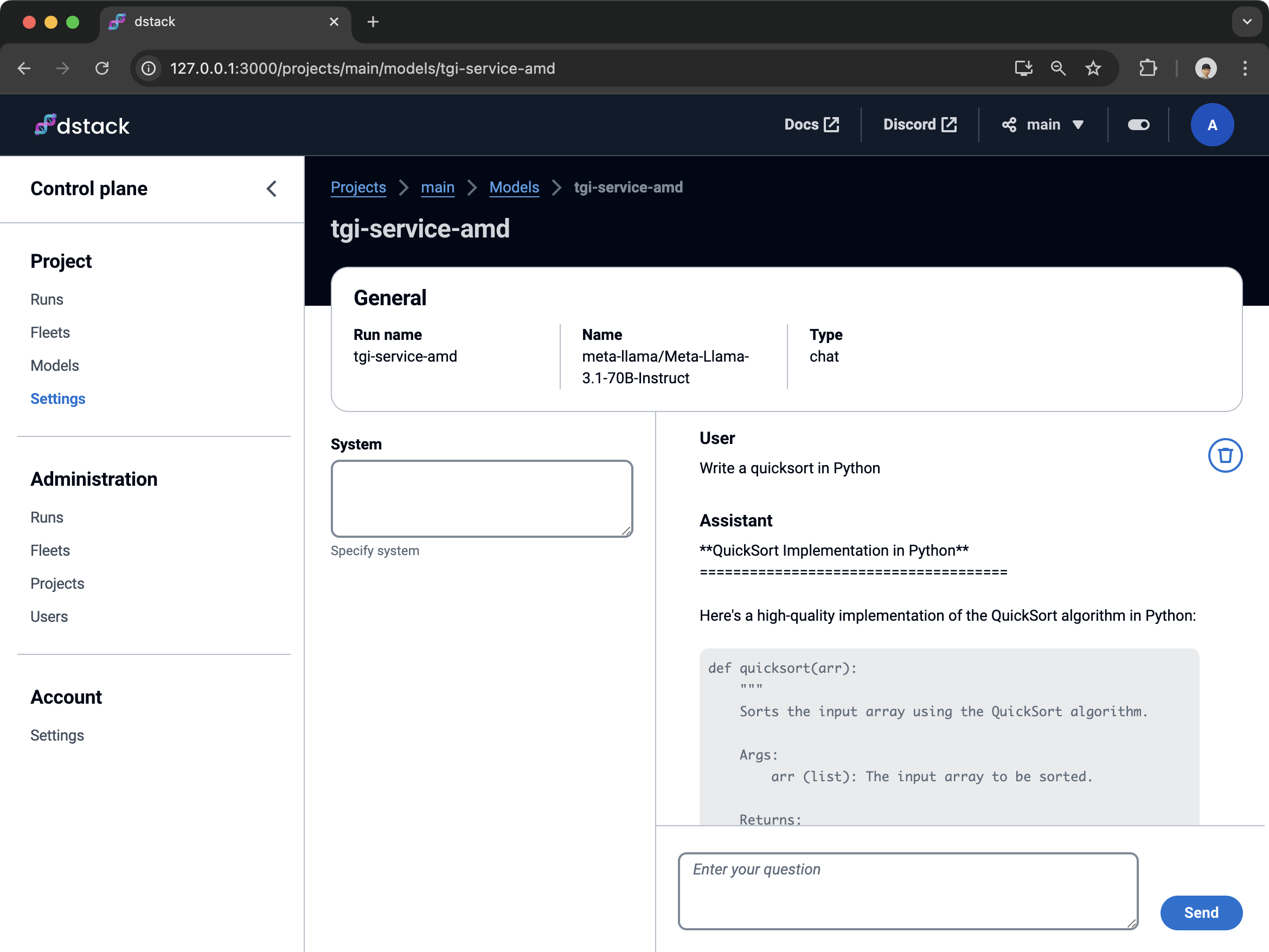
Control plane
If you specify model when running a service, dstack will automatically register the model on
an OpenAI-compatible endpoint and allow you to use it for chat via the control plane UI.
Memory requirements¶
Below are the approximate memory requirements for serving LLMs with their corresponding TPUs.
| Model size | bfloat16 | TPU | int8 | TPU |
|---|---|---|---|---|
| 8B | 16GB | v5litepod-4 | 8GB | v5litepod-4 |
| 70B | 140GB | v5litepod-16 | 70GB | v5litepod-16 |
| 405B | 810GB | v5litepod-64 | 405GB | v5litepod-64 |
Note, v5litepod is optimized for serving transformer-based models. Each core is equipped with 16GB of memory.
Supported frameworks¶
| Framework | Quantization | Note |
|---|---|---|
| TGI | bfloat16 | To deploy with TGI, Optimum TPU must be used. |
| vLLM | int8, bfloat16 | int8 quantization still requires the same memory because the weights are first moved to the TPU in bfloat16, and then converted to int8. See the pull request for more details. |
Running a configuration¶
Once the configuration is ready, run dstack apply -f <configuration file>, and dstack will automatically provision the
cloud resources and run the configuration.
Fine-tuning¶
Below is an example of fine-tuning Llama 3.1 8B using Optimum TPU and the Abirate/english_quotes dataset.
type: task
name: optimum-tpu-llama-train
python: "3.11"
env:
- HF_TOKEN
commands:
- git clone -b add_llama_31_support https://github.com/dstackai/optimum-tpu.git
- mkdir -p optimum-tpu/examples/custom/
- cp examples/single-node-training/optimum-tpu/llama31/train.py optimum-tpu/examples/custom/train.py
- cp examples/single-node-training/optimum-tpu/llama31/config.yaml optimum-tpu/examples/custom/config.yaml
- cd optimum-tpu
- pip install -e . -f https://storage.googleapis.com/libtpu-releases/index.html
- pip install datasets evaluate
- pip install accelerate -U
- pip install peft
- python examples/custom/train.py examples/custom/config.yaml
resources:
gpu: v5litepod-8
Memory requirements¶
Below are the approximate memory requirements for fine-tuning LLMs with their corresponding TPUs.
| Model size | LoRA | TPU |
|---|---|---|
| 8B | 16GB | v5litepod-8 |
| 70B | 160GB | v5litepod-16 |
| 405B | 950GB | v5litepod-64 |
Note, v5litepod is optimized for fine-tuning transformer-based models. Each core is equipped with 16GB of memory.
Supported frameworks¶
| Framework | Quantization | Note |
|---|---|---|
| TRL | bfloat16 | To fine-tune using TRL, Optimum TPU is recommended. TRL doesn't support Llama 3.1 out of the box. |
| Pytorch XLA | bfloat16 |
What's next?¶
- Browse Optimum TPU, Optimum TPU TGI and vLLM.
- Check dev environments, tasks, services, and fleets.
Multi-host TPUs
If you’d like to use dstack with more than eight TPU cores, upvote the corresponding
issue.