Benchmarking AMD GPUs: bare-metal, VMs¶
This is the first in our series of benchmarks exploring the performance of AMD GPUs in virtualized versus bare-metal environments. As cloud infrastructure increasingly relies on virtualization, a key question arises: can VMs match bare-metal performance for GPU-intensive tasks? For this initial investigation, we focus specifically on a single-GPU setup, comparing a containerized workload on a VM against a bare-metal server, both equipped with the powerful AMD MI300X GPU.

Our findings reveal that for single-GPU LLM training and inference, both setups deliver comparable performance. The subtle differences we observed highlight how virtualization overhead can influence performance under specific conditions, but for most practical purposes, the performance is nearly identical.
This benchmark was supported by Hot Aisle, a provider of AMD GPU bare-metal and VM infrastructure.
Benchmark 1: Inference¶
Finding 1: Identical performance at moderate concurrency levels and slightly worse otherwise¶
Throughput vs latency
Comparing throughput (tokens/second) against end-to-end latency across multiple concurrency levels is an effective way to measure an LLM inference system's scalability and responsiveness. This benchmark reveals how VM and bare-metal environments handle varying loads and pinpoints their throughput saturation points.
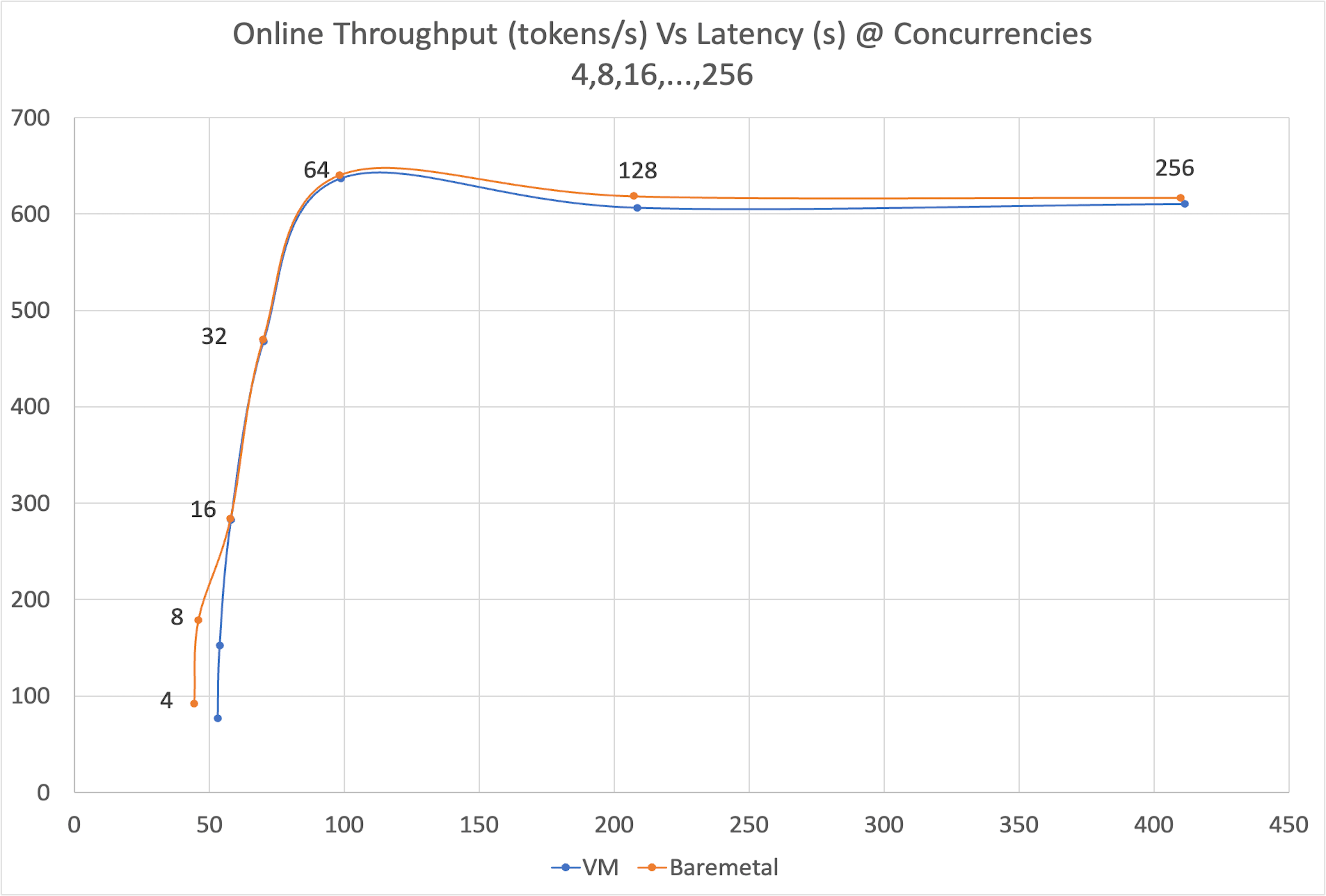
At moderate concurrency levels (16–64), both bare-metal and VM deliver near-identical inference performance. At lower levels (4-16), bare-metal shows slightly better throughput, likely due to faster kernel launches and direct device access. At high concurrency (64–128), bare-metal maintains a slight edge in latency and throughput. At a concurrency of 256, throughput saturates for both, suggesting a bottleneck from KV cache pressure on GPU memory.
Benchmark 2: Training¶
Finding 1: Identical performance at large batches with only minor variations¶
For training, we compare throughput (samples/second) and total runtime across increasing batch sizes. These metrics are crucial for evaluating cost and training efficiency.
Throughput
Bare metal performs slightly better at small batch sizes, but the VM consistently shows slightly better throughput and runtime at larger batch sizes (≥8).
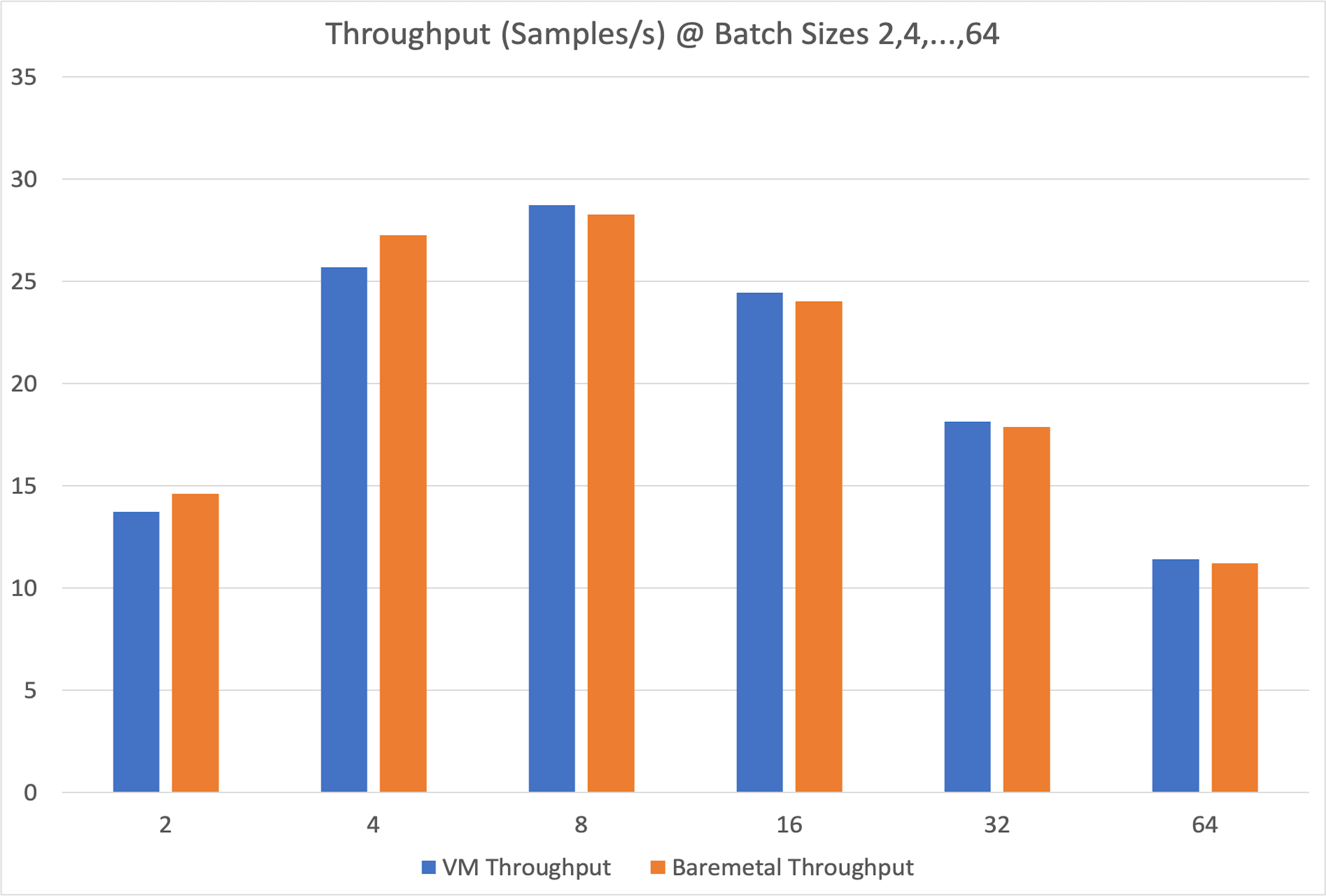
This may be because larger batches are compute-bound, making CPU-GPU synchronization less frequent.
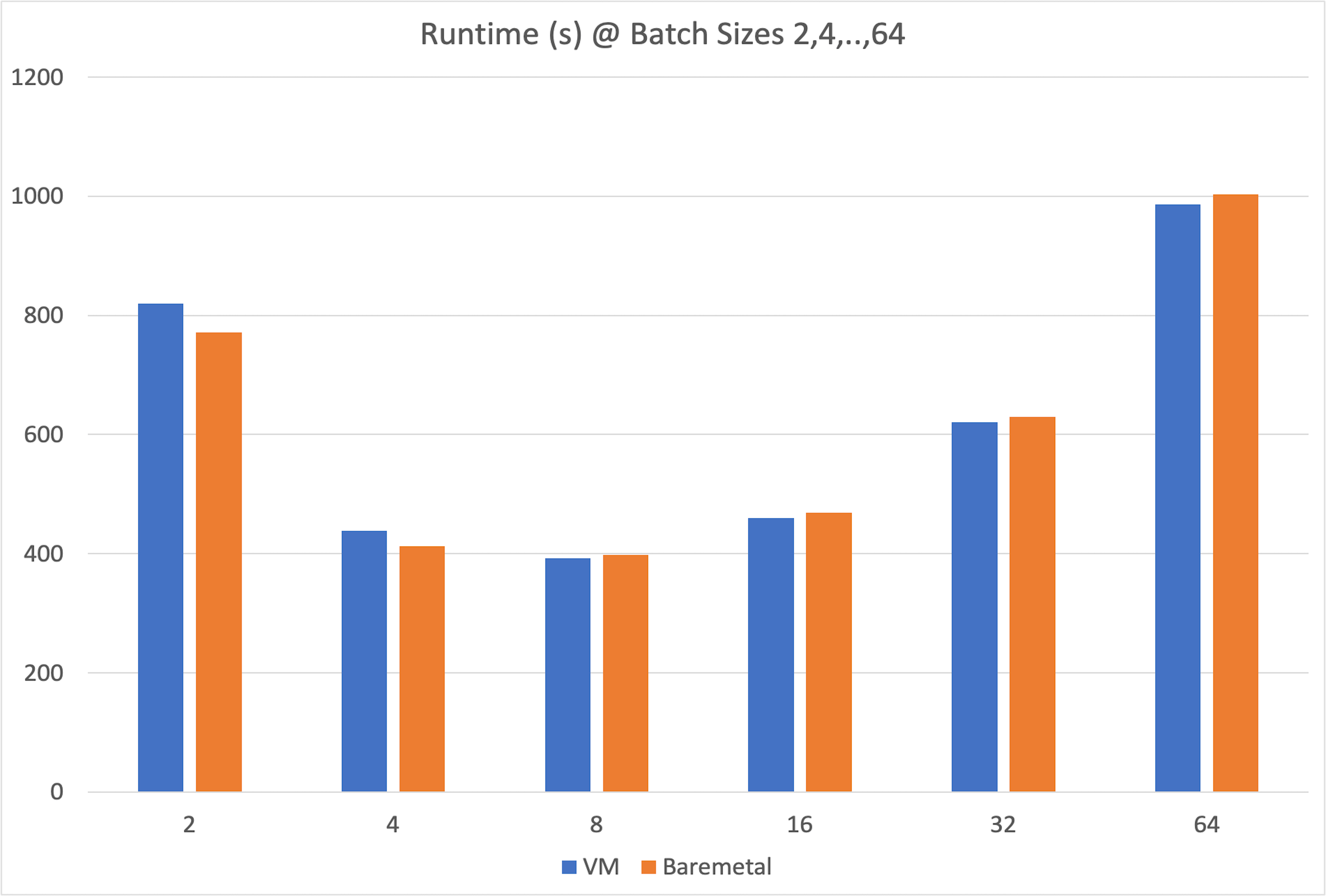
One plausible explanation for the VM's slight advantage here is that in the bare-metal setup, using only one of eight available GPUs may lead to minor interference from shared background services.
Finding 2: Identical convergence, GPU utilization, memory consumption¶
Training/eval loss, GPU utilization, and VRAM usage are key indicators of training stability and system efficiency. Loss shows model convergence, while utilization and memory reflect hardware efficiency.
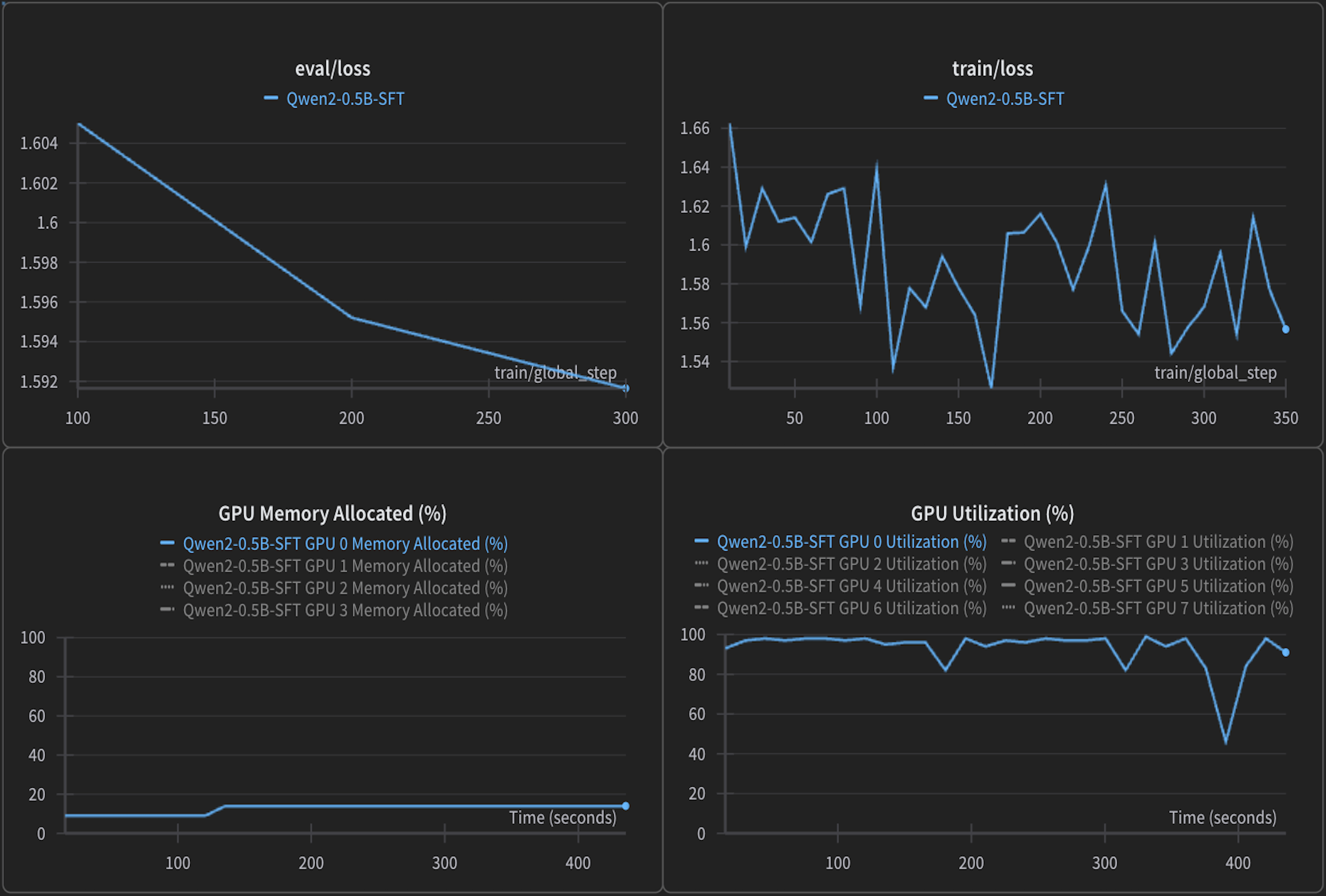
Both VM and bare-metal setups exhibited nearly identical training and evaluation loss curves, indicating consistent model convergence. GPU utilization remained high (~95–100%) and stable in both environments, with similar VRAM consumption.
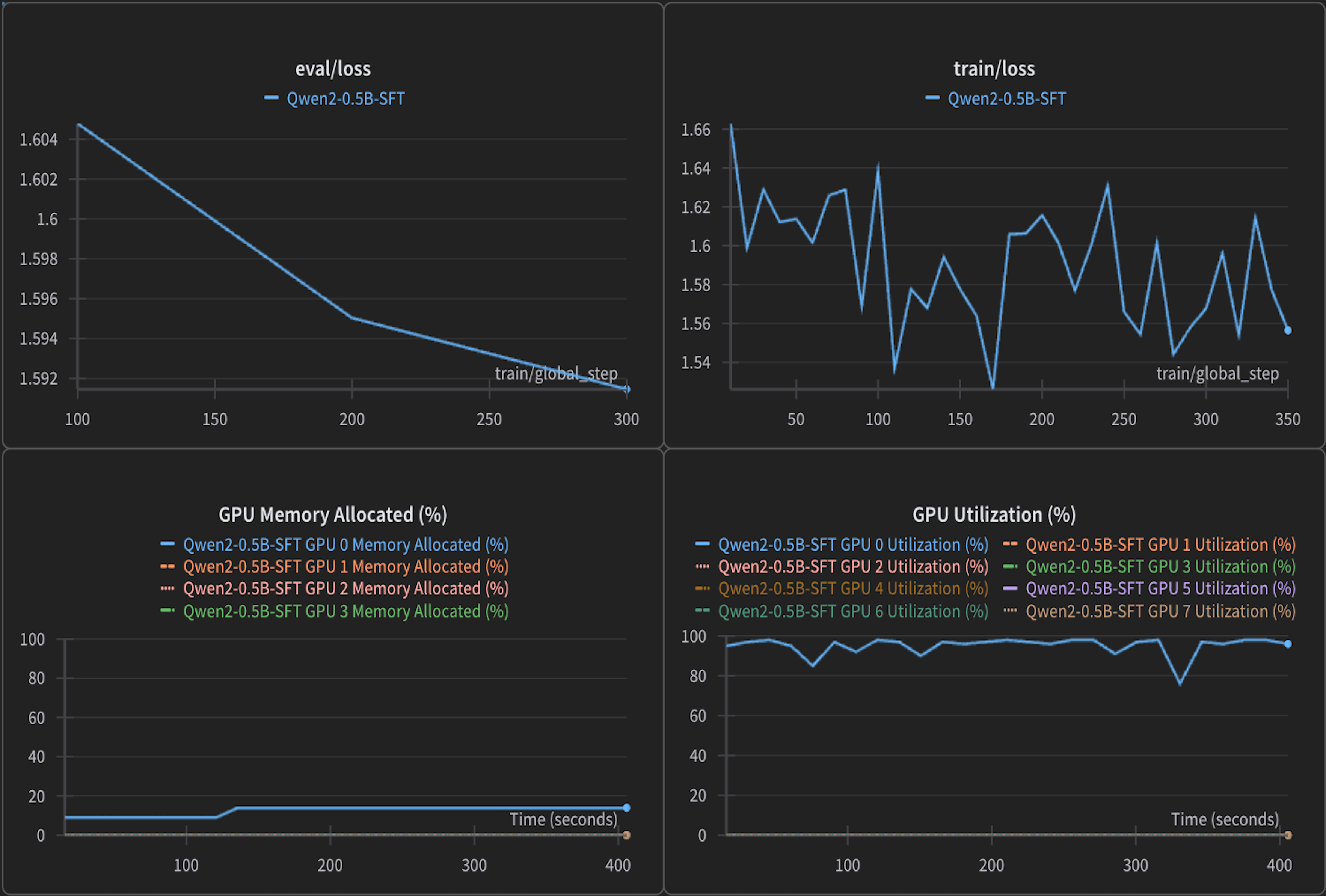
This demonstrates that from a model training and hardware utilization perspective, both setups are equally efficient.
Limitations¶
Multi-GPU
This initial benchmark deliberately focused on a single-GPU setup to establish a baseline. A more production-representative evaluation would compare multi-GPU VMs with multi-GPU bare-metal systems. In multi-GPU inference, bare-metal’s direct hardware access could offer an advantage. For distributed training, however, where all GPUs are fully engaged, the performance between VM and bare-metal would likely be even closer.
Furthermore, it's important to note that the performance gap in virtualized setups can potentially be narrowed significantly with expert hypervisor tuning, such as CPU pinning and NUMA node alignment.
Multi-node
For distributed training, models are trained across multi-node clusters where control-plane operations rely on the CPU. This can impact interconnect bandwidth and overall performance. A future comparison is critical, as performance will heavily depend on the network virtualization technology used.
For instance, testing setups that use SR-IOV (Single Root I/O Virtualization)—a technology designed to provide near-native network performance to VMs—would be essential for a complete picture.
Conclusion¶
Our initial benchmark shows that performance differences between a VM and bare-metal are minimal. Both environments exhibit near-identical behavior aside from a few subtle variations. These findings suggest that VMs are a highly viable option for demanding GPU tasks, with only minor trade-offs under specific conditions, and that AMD GPUs deliver exceptional performance in both virtualized and bare-metal environments.
Benchmark setup¶
Hardware configuration¶
VM
- CPU: Intel Xeon Platinum 8470: 13c @ 2 GHz
- RAM: 224 GiB
- NVMe: 13 TB
- GPUs: 1 x AMD MI300X
Bare-metal
- CPU: Intel Xeon Pla*tinum 8470: 13c @ 2 GHz (
--cpuset-cpus="0-12") - RAM: 224 GiB (
--memory="224g") - GPUs: 1x AMD MI300X
Benchmark methodology¶
The steps to run benchmarks are identical for both setups, except that the docker run command for bare metal includes --cpuset-cpus="0-12" and --memory="224g" to match the VM's resources.
Inference¶
- Run a
rocm/vllmcontainer:
docker run -it \
--network=host \
--group-add=video \
--ipc=host \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
rocm/vllm:latest /bin/bash
- Start the vLLM server:
vllm serve meta-llama/Llama-3.3-70B-Instruct --max-model-len 100000
- Start the benchmark
isl=1024
osl=1024
MaxConcurrency="4 8 16 32 64 128 256"
RESULT_DIR="./results_concurrency_sweep"
mkdir -p $RESULT_DIR
for concurrency in $MaxConcurrency; do
TIMESTAMP=$(date +%Y%m%d-%H%M%S)
FILENAME="llama3.3-70B-random-${concurrency}concurrency-${TIMESTAMP}.json"
python3 /app/vllm/benchmarks/benchmark_serving.py \
--model meta-llama/Llama-3.3-70B-Instruct \
--dataset-name random \
--random-input-len $isl \
--random-output-len $osl \
--num-prompts $((10 * $concurrency)) \
--max-concurrency $concurrency \
--ignore-eos \
--percentile-metrics ttft,tpot,e2el \
--save-result \
--result-dir "$RESULT_DIR" \
--result-filename "$FILENAME"
done
Training¶
- Run the
rocm/dev-ubuntu-22.04:6.4-completecontainer:
docker run -it \
--network=host \
--group-add=video \
--ipc=host \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
rocm/dev-ubuntu-22.04:6.4-complete /bin/bash
- Install TRL:
sudo apt-get update && sudo apt-get install -y git cmake && \
pip install torch --index-url https://download.pytorch.org/whl/nightly/rocm6.4 && \
pip install transformers peft wandb && \
git clone https://github.com/huggingface/trl && \
cd trl && \
pip install .
- Run the benchmark
python3 trl/scripts/sft.py \
--model_name_or_path Qwen/Qwen2-0.5B \
--dataset_name trl-lib/Capybara \
--learning_rate 2.0e-4 \
--num_train_epochs 1 \
--packing \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--gradient_checkpointing \
--eos_token '<|im_end|>' \
--eval_strategy steps \
--eval_steps 100 \
--use_peft \
--lora_r 32 \
--lora_alpha 16
Source code¶
All source code and findings are available in our GitHub repo.
References¶
What's next?¶
Our next steps are to benchmark VM vs. bare-metal performance in multi-GPU and multi-node setups, covering tensor-parallel inference and distributed training scenarios.
Acknowledgments¶
Hot Aisle¶
Big thanks to Hot Aisle for providing the compute power behind these benchmarks. If you’re looking for fast AMD GPU bare-metal or VM instances, they’re definitely worth checking out.