Benchmarking Llama 3.1 405B on 8x AMD MI300X GPUs¶
At dstack, we've been adding support for AMD GPUs with SSH fleets,
so we saw this as a great chance to test our integration by benchmarking AMD GPUs. Our friends at
Hot Aisle, who build top-tier
bare metal compute for AMD GPUs, kindly provided the hardware for the benchmark.
With access to a bare metal machine with 8x AMD MI300X GPUs from Hot Aisle, we decided to skip smaller models and went with Llama 3.1 405B. To make the benchmark interesting, we tested how inference performance varied across different backends (vLLM and TGI) and use cases (real-time vs batch inference, different context sizes, etc.).
Benchmark setup¶
Here is the spec of the bare metal machine we got:
- Intel® Xeon® Platinum 8470 2G, 52C/104T, 16GT/s, 105M Cache, Turbo, HT (350W) [x2]
- AMD MI300X GPU OAM 192GB 750W GPUs [x8]
- 64GB RDIMM, 4800MT/s Dual Rank [x32]
Set up an SSH fleet
Hot Aisle provided us with SSH access to the machine. To make it accessible via dstack,
we created an SSH fleet using the following configuration:
type: fleet
name: hotaisle-fleet
placement: any
ssh_config:
user: hotaisle
identity_file: ~/.ssh/hotaisle_id_rsa
hosts:
- hostname: ssh.hotaisle.cloud
port: 22013
After running dstack apply -f hotaisle.dstack.yml, we were ready to run dev environments, tasks, and services on
this fleet via datack.
vLLM
PyTorch version: 2.4.1+rocm6.1
Is debug build: False
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: 6.1.40091-a8dbc0c19
OS: Ubuntu 22.04.4 LTS (x86_64)
GCC version: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Clang version: 17.0.0 (https://github.com/RadeonOpenCompute/llvm-project roc-6.1.0 24103 7db7f5e49612030319346f900c08f474b1f9023a)
CMake version: version 3.26.4
Libc version: glibc-2.35
Python version: 3.10.14 (main, Mar 21 2024, 16:24:04) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-6.8.0-45-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: AMD Instinct MI300X (gfx942:sramecc+:xnack-)
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: 6.1.40093
MIOpen runtime version: 3.1.0
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==1.4.1
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.26.4
[pip3] pytorch-triton-rocm==3.0.0
[pip3] pyzmq==24.0.1
[pip3] torch==2.4.1+rocm6.1
[pip3] torchaudio==2.4.1+rocm6.1
[pip3] torchvision==0.16.1+fdea156
[pip3] transformers==4.45.1
[pip3] triton==3.0.0
[conda] No relevant packages
ROCM Version: 6.1.40091-a8dbc0c19
Neuron SDK Version: N/A
vLLM Version: 0.6.3.dev116+g151ef4ef
vLLM Build Flags:
CUDA Archs: Not Set; ROCm: Disabled; Neuron: Disabled
TGI
The ghcr.io/huggingface/text-generation-inference:sha-11d7af7-rocm Docker image was used.
For conducting the tests, we've been using the benchmark_serving provided by vLLM.
Observations¶
Token/sec per batch size¶
TGI consistently exceeds vLLM in token throughput across all batch sizes, with the performance difference growing larger as the batch size increases. For batch sizes exceeding 64, the performance disparity becomes quite notable.
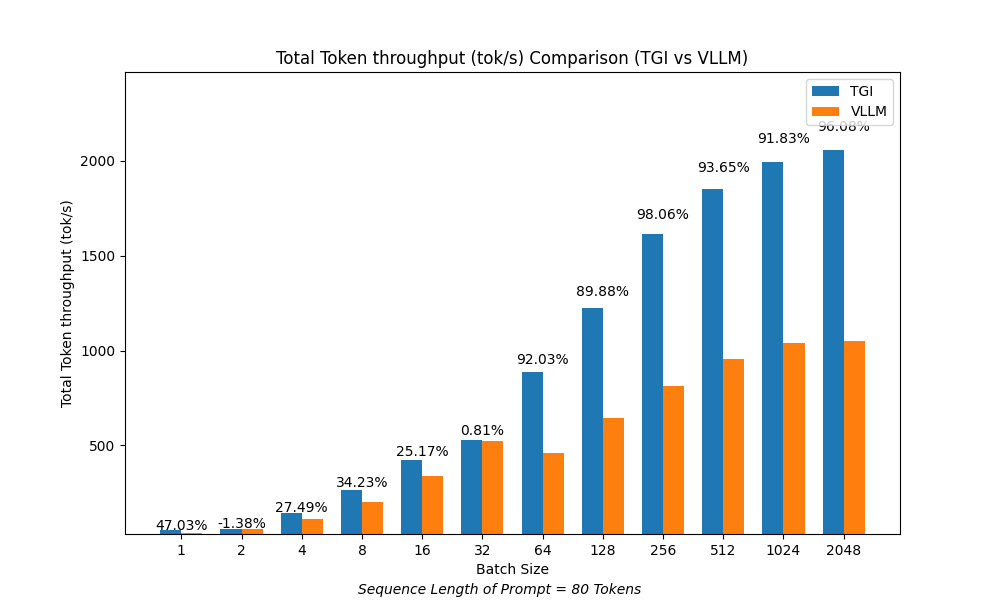
The prompts maintain a constant sequence length of 80 tokens each.
TTFT per batch size¶
TGI surpasses vLLM in Time to First Token for all batch sizes, except for batch sizes 2 and 32.

The performance difference is considerable for larger batch sizes.
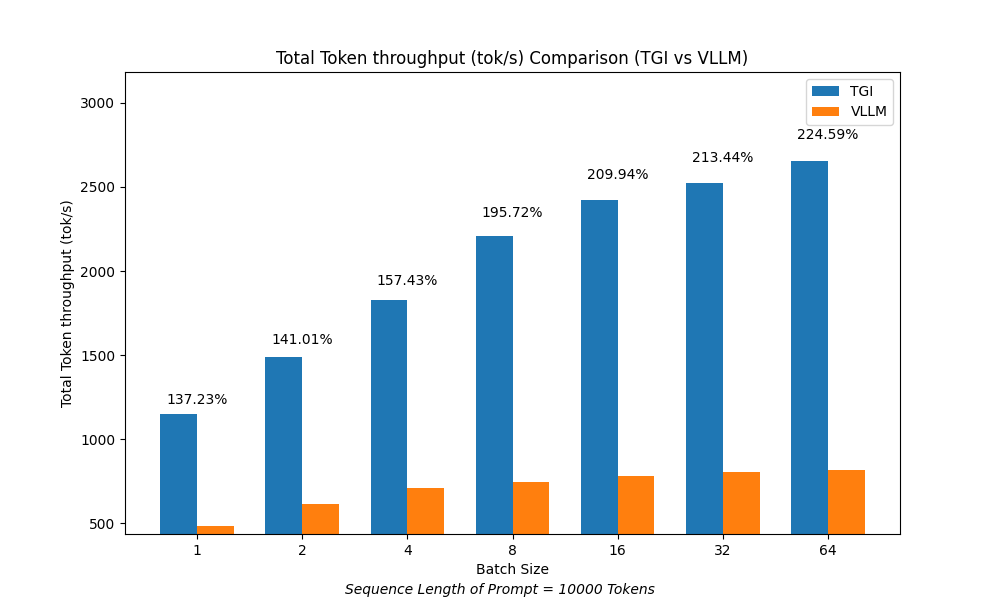
Token/sec per context size¶
To evaluate performance with larger prompt sizes, we conducted tests using prompts of 10,000 tokens.
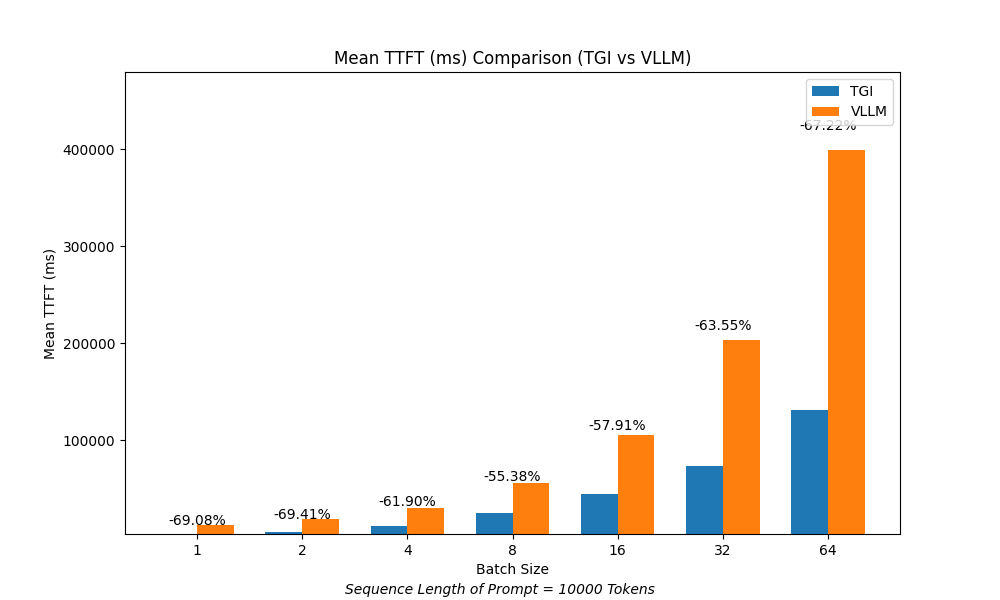
TTFT per context size¶
In this case, TGI demonstrated an advantage over vLLM in both token throughput and time to first token (TTFT).
Token/sec and TTFT per RPS¶
To assess the performance scalability of TGI and vLLM, we conducted tests by gradually increasing the Requests Per Second (RPS) and the total Requests Sent (RS) while keeping the prompt size consistent at 1,000 tokens for all trials.
In this experiment, we initiated requests beginning with 30 requests at 1 RPS, then increased to 60 requests at 2 RPS, and continued this pattern up to 150 requests at 5 RPS.

Ideally, we would expect all trials to complete within the same time frame. However, due to resource limitations and increasing resource utilization, higher RPS does not lead to a proportional increase in throughput (tokens per second) or maintain Time to First Token (TTFT).
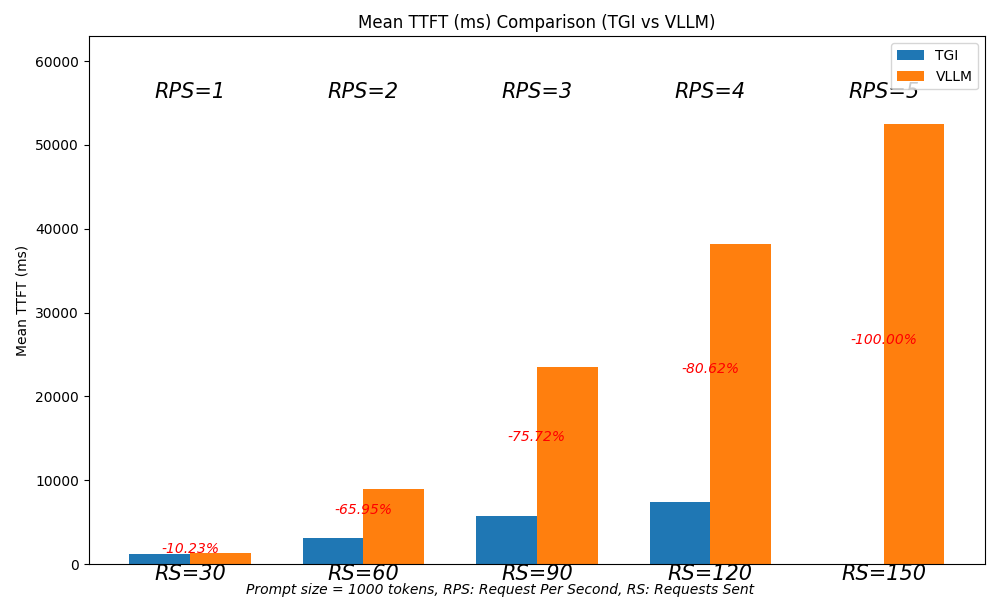
At 1 RPS, vLLM performs slightly better than TGI. However, between 2 and 4 RPS, TGI outperforms vLLM in both throughput and TTFT.
Notably, TGI begins to drop requests once it reaches 5 RPS.
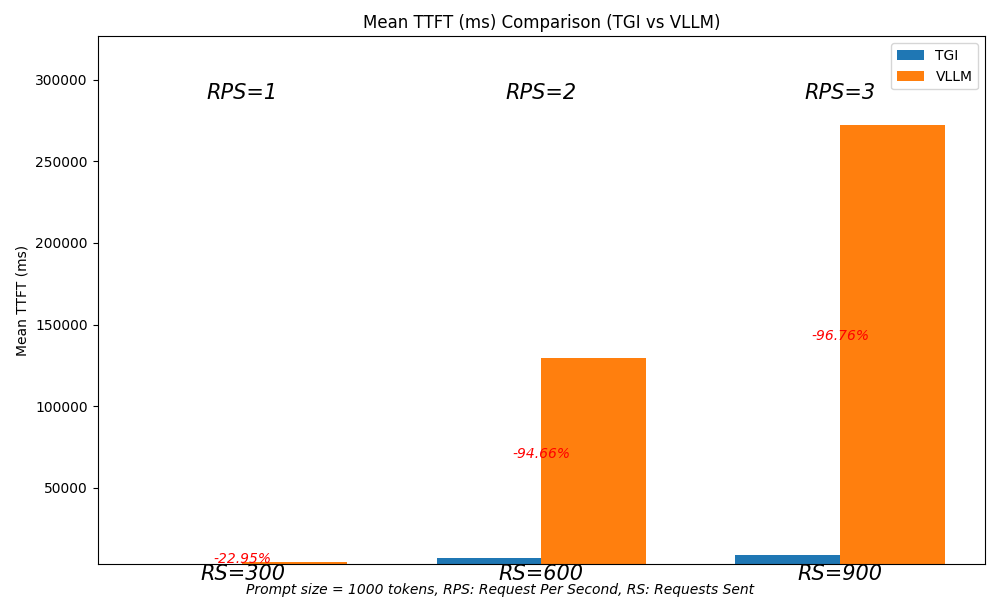
We repeated the test using a higher number of requests, ranging from 300 to 900.
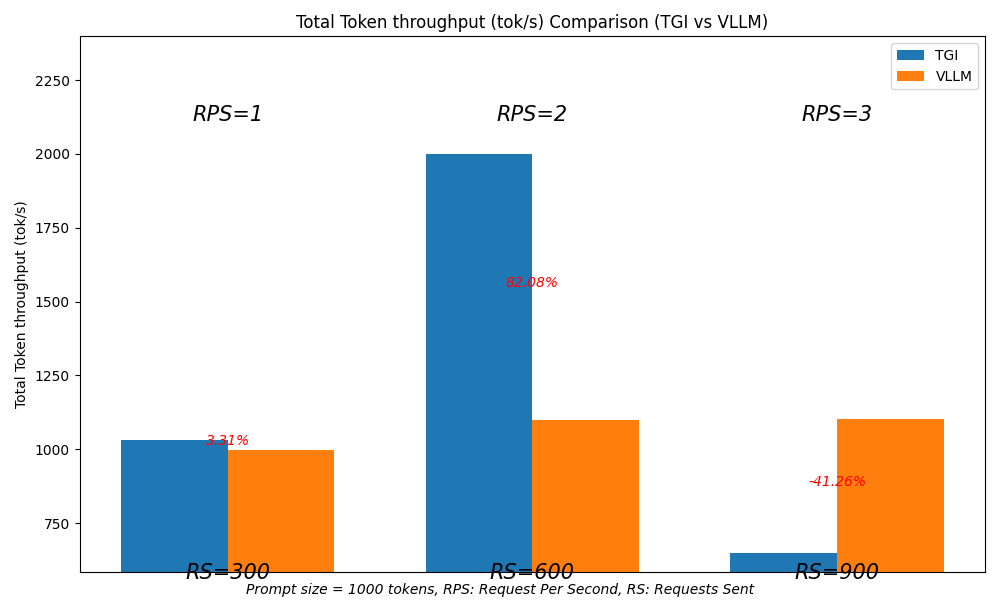
At 900 requests with a rate of 3 requests per second (RPS), TGI dropped a majority of the requests. However, its performance improved notably when the number of requests was below 900.
VRAM consumption¶
When considering VRAM consumption right after loading model weights, TGI allocates approximately 28% less VRAM compared to vLLM.
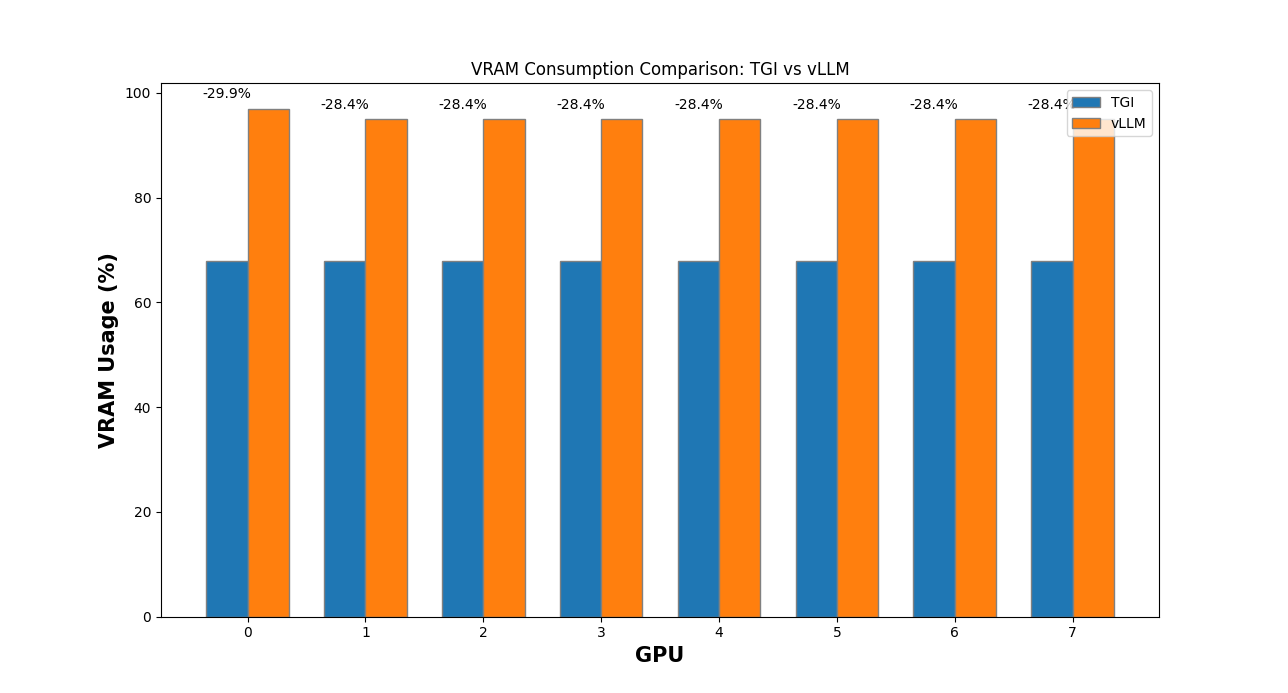
This difference may be related to how vLLM pre-allocates GPU cache.
Conclusion¶
- For small sequence lengths, starting with a batch size of 64, TGI significantly outperforms vLLM in terms of throughput and TTFT.
- For larger sequence lengths, TGI outperforms vLLM even more in both throughput and TTFT, with the difference increasing as the batch size grows.
- At higher request rates, TGI continues to outperform vLLM, likely due to its superior ability to batch requests efficiently.
Limitation
- In certain circumstances (e.g., at higher request rates), for unknown reasons, TGI dropped requests, making it impossible to accurately track throughput and TTFT.
- With vLLM, we used the default backend configuration. With better tuning, we might have achieved improved performance.
In general, the 8x AMD MI300X is a good fit for larger models and allows us to make the most of its VRAM, especially for larger batches.
If you’d like to support us in doing more benchmarks, please let us know.
What's next?¶
While we wait for AMD to announce new GPUs and for data centers to offer them, we’re considering tests with NVIDIA GPUs like the H100 and H200, as well as possibly Google TPU.
Also, the next step is to measure how the FP8 version of the model would perform on this hardware.
Source code¶
The source code used for this benchmark can be found in our GitHub repo.
If you have questions, feedback, or want to help improve the benchmark, please reach out to our team.
Thanks to our friends¶
Hot Aisle¶
Hot Aisle is the primary sponsor of this benchmark, and we are sincerely grateful for their hardware and support.
If you'd like to use top-tier bare metal compute with AMD GPUs, we recommend going
with Hot Aisle. Once you gain access to a cluster, it can be easily accessed via dstack's SSH fleet easily.
Runpod¶
If you’d like to use on-demand compute with AMD GPUs at affordable prices, you can configure dstack to
use Runpod. In
this case, dstack will be able to provision fleets automatically when you run dev environments, tasks, and
services.