Server deployment
The dstack server can run on your laptop or any environment with access to the cloud and on-prem clusters you plan to use.
The minimum hardware requirements for running the server are 1 CPU and 1GB of RAM.
The server can be set up via
pipon Linux, macOS, and Windows (via WSL 2). It requires Git and OpenSSH.
$ pip install "dstack[all]" -U
$ dstack server
Applying ~/.dstack/server/config.yml...
The admin token is "bbae0f28-d3dd-4820-bf61-8f4bb40815da"
The server is running at http://127.0.0.1:3000/
The server can be set up via
uvon Linux, macOS, and Windows (via WSL 2). It requires Git and OpenSSH.
$ uv tool install 'dstack[all]' -U
$ dstack server
Applying ~/.dstack/server/config.yml...
The admin token is "bbae0f28-d3dd-4820-bf61-8f4bb40815da"
The server is running at http://127.0.0.1:3000/
To deploy the server most reliably, it's recommended to use
dstackai/dstackDocker image.
$ docker run -p 3000:3000 \
-v $HOME/.dstack/server/:/root/.dstack/server \
dstackai/dstack
Applying ~/.dstack/server/config.yml...
The admin token is "bbae0f28-d3dd-4820-bf61-8f4bb40815da"
The server is running at http://127.0.0.1:3000/
AWS CloudFormation
If you'd like to deploy the server to a private AWS VPC, you can use our CloudFormation template.
First, ensure you've set up a private VPC with public and private subnets.
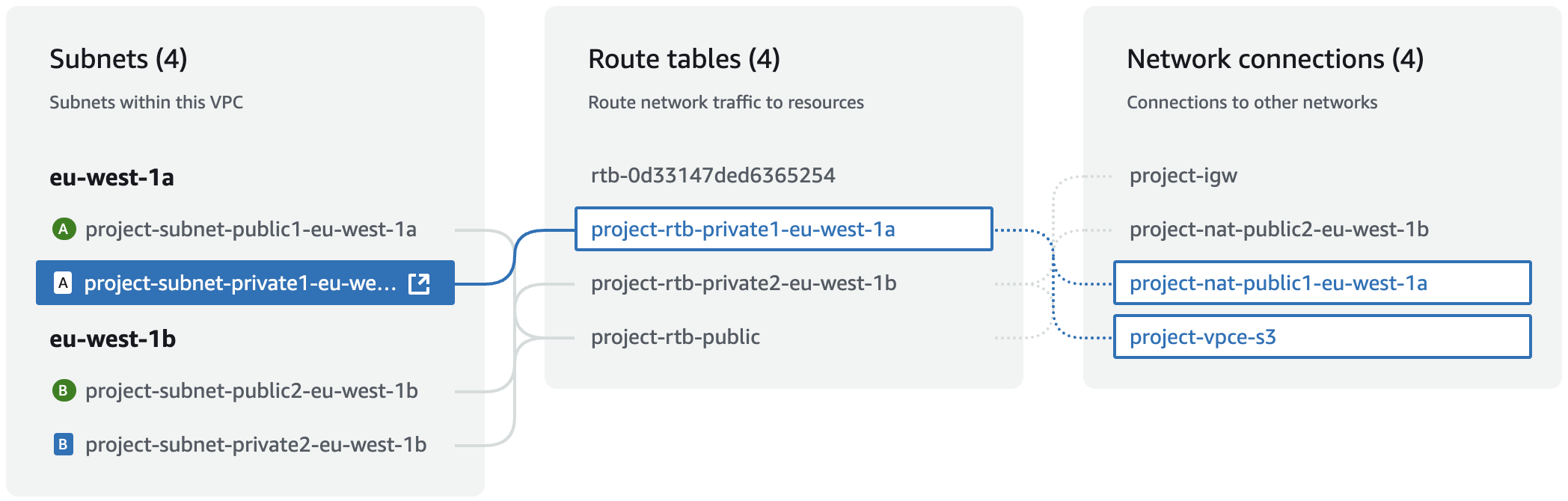
Create a stack using the template, and specify the VPC and private subnets.
Once, the stack is created, go to Outputs for the server URL and admin token.
To access the server URL, ensure you're connected to the VPC, e.g. via VPN client.
If you'd like to adjust anything, the source code of the template can be found at
examples/server-deployment/cloudformation/template.yaml.
Backend configuration¶
To use dstack with cloud providers, configure backends
via the ~/.dstack/server/config.yml file.
The server loads this file on startup.
Alternatively, you can configure backends on the project settings page via UI.
For using
dstackwith on-prem servers, no backend configuration is required. Use SSH fleets instead.
State persistence¶
The dstack server can store its internal state in SQLite or Postgres.
By default, it stores the state locally in ~/.dstack/server using SQLite.
With SQLite, you can run at most one server replica.
Postgres has no such limitation and is recommended for production deployment.
Replicate SQLite to cloud storage
You can configure automatic replication of your SQLite state to a cloud object storage using Litestream. This allows persisting the server state across re-deployments when using SQLite.
To enable Litestream replication, set the following environment variables:
LITESTREAM_REPLICA_URL- The url of the cloud object storage. Examples:s3://<bucket-name>/<path>,gcs://<bucket-name>/<path>,abs://<storage-account>@<container-name>/<path>, etc.
You also need to configure cloud storage credentials.
AWS S3
To persist state into an AWS S3 bucket, provide the following environment variables:
AWS_ACCESS_KEY_ID- The AWS access key IDAWS_SECRET_ACCESS_KEY- The AWS secret access key
GCP Storage
To persist state into a GCP Storage bucket, provide one of the following environment variables:
GOOGLE_APPLICATION_CREDENTIALS- The path to the GCP service account key JSON fileGOOGLE_APPLICATION_CREDENTIALS_JSON- The GCP service account key JSON
Azure Blob Storage
To persist state into an Azure blog storage, provide the following environment variable.
LITESTREAM_AZURE_ACCOUNT_KEY- The Azure storage account key
More details on options for configuring replication.
PostgreSQL¶
To store the server state in Postgres, set the DSTACK_DATABASE_URL environment variable:
$ DSTACK_DATABASE_URL=postgresql+asyncpg://user:password@db-host:5432/dstack dstack server
The minimum requirements for the DB instance are 2 CPU, 2GB of RAM, and at least 50 max_connections per server replica
or a configured connection pooler to handle that many connections.
If you're using a smaller DB instance, you may need to set lower DSTACK_DB_POOL_SIZE and DSTACK_DB_MAX_OVERFLOW, e.g.
DSTACK_DB_POOL_SIZE=10 and DSTACK_DB_MAX_OVERFLOW=0.
Migrate from SQLite to PostgreSQL
You can migrate the existing state from SQLite to PostgreSQL using pgloader:
- Create a new PostgreSQL database
- Clone the
dstackrepo and installdstackfrom source. Ensure you've checked out the tag that corresponds to your server version (e.g.git checkout 0.18.10). - Apply database migrations to the new database:
cd src/dstack/_internal/server/ export DSTACK_DATABASE_URL="postgresql+asyncpg://..." alembic upgrade head - Install pgloader
- Pass the path to the
~/.dstack/server/data/sqlite.dbfile toSOURCE_PATHand setTARGET_PATHwith the URL of the PostgreSQL database. Example:Thecd scripts/ export SOURCE_PATH=sqlite:///Users/me/.dstack/server/data/sqlite.db export TARGET_PATH=postgresql://postgres:postgres@localhost:5432/postgres pgloader sqlite_to_psql.loadpgloaderscript will migrate the SQLite data to PostgreSQL. It may emit warnings that are safe to ignore.
If you encounter errors, please submit an issue.
Logs storage¶
By default, dstack stores workload logs locally in ~/.dstack/server/projects/<project_name>/logs.
For multi-replica server deployments, it's required to store logs externally.
dstack supports storing logs using AWS CloudWatch, GCP Logging, or Fluent-bit with Elasticsearch / Opensearch.
AWS CloudWatch¶
To store logs in AWS CloudWatch, set the DSTACK_SERVER_CLOUDWATCH_LOG_GROUP and
the DSTACK_SERVER_CLOUDWATCH_LOG_REGION environment variables.
The log group must be created beforehand. dstack won't try to create it.
Required permissions
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DstackLogStorageAllow",
"Effect": "Allow",
"Action": [
"logs:DescribeLogStreams",
"logs:CreateLogStream",
"logs:GetLogEvents",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:::log-group:<group name>",
"arn:aws:logs:::log-group:<group name>:*"
]
}
]
}
GCP Logging¶
To store logs using GCP Logging, set the DSTACK_SERVER_GCP_LOGGING_PROJECT environment variable.
Required permissions
Ensure you've configured Application Default Credentials with the following permissions:
logging.logEntries.create
logging.logEntries.list
Logs management
dstack writes all the logs to the projects/[PROJECT]/logs/dstack-run-logs log name.
If you want to set up a custom retention policy for dstack logs, create a new bucket and configure a sink:
$ gcloud logging buckets create dstack-bucket \
--location=global \
--description="Bucket for storing dstack run logs" \
--retention-days=10
$ gcloud logging sinks create dstack-sink \
logging.googleapis.com/projects/[PROJECT]/locations/global/buckets/dstack-bucket \
--log-filter='logName = "projects/[PROJECT]/logs/dstack-run-logs"'
Fluent-bit¶
To store logs using Fluent-bit, set the DSTACK_SERVER_FLUENTBIT_HOST environment variable.
Fluent-bit supports two modes depending on how you want to access logs.
Logs are shipped to Fluent-bit and can be read back through the dstack UI and CLI via Elasticsearch or OpenSearch.
Use this mode when you want a complete integration with log viewing in dstack:
$ DSTACK_SERVER_FLUENTBIT_HOST=fluentbit.example.com \
DSTACK_SERVER_ELASTICSEARCH_HOST=https://elasticsearch.example.com:9200 \
dstack server
Logs are forwarded to Fluent-bit but cannot be read through dstack.
The dstack UI/CLI will show empty logs. Use this mode when:
- You have an existing logging infrastructure (Kibana, Grafana, Datadog, etc.)
- You only need to forward logs without reading them back through
dstack - You want to reduce operational complexity by not running Elasticsearch/OpenSearch
$ DSTACK_SERVER_FLUENTBIT_HOST=fluentbit.example.com \
dstack server
Additional configuration
The following optional environment variables can be used to customize the Fluent-bit integration:
Fluent-bit settings:
DSTACK_SERVER_FLUENTBIT_PORT– The Fluent-bit port. Defaults to24224.DSTACK_SERVER_FLUENTBIT_PROTOCOL– The protocol to use:forwardorhttp. Defaults toforward.DSTACK_SERVER_FLUENTBIT_TAG_PREFIX– The tag prefix for logs. Defaults todstack.
Elasticsearch/OpenSearch settings (for full mode only):
DSTACK_SERVER_ELASTICSEARCH_HOST– The Elasticsearch/OpenSearch host for reading logs. If not set, runs in ship-only mode.DSTACK_SERVER_ELASTICSEARCH_INDEX– The Elasticsearch/OpenSearch index pattern. Defaults todstack-logs.DSTACK_SERVER_ELASTICSEARCH_API_KEY– The Elasticsearch/OpenSearch API key for authentication.
Fluent-bit configuration
Configure Fluent-bit to receive logs and forward them to Elasticsearch or OpenSearch. Example configuration:
[INPUT]
Name forward
Listen 0.0.0.0
Port 24224
[OUTPUT]
Name es
Match dstack.*
Host elasticsearch.example.com
Port 9200
Index dstack-logs
Suppress_Type_Name On
Required dependencies
To use Fluent-bit log storage, install the fluentbit extras:
$ pip install "dstack[all]" -U
# or
$ pip install "dstack[fluentbit]" -U
File storage¶
When using files or repos, dstack uploads local files and diffs to the server so that you can have access to them within runs. By default, the files are stored in the DB and each upload is limited to 2MB. You can configure an object storage to be used for uploads and increase the default limit by setting the DSTACK_SERVER_CODE_UPLOAD_LIMIT environment variable
S3¶
To use S3 for storing uploaded files, set the DSTACK_SERVER_S3_BUCKET and DSTACK_SERVER_S3_BUCKET_REGION environment variables.
The bucket must be created beforehand. dstack won't try to create it.
Required permissions
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<bucket-name>",
"arn:aws:s3:::<bucket-name>/*"
]
}
]
}
GCS¶
To use GCS for storing uploaded files, set the DSTACK_SERVER_GCS_BUCKET environment variable.
The bucket must be created beforehand. dstack won't try to create it.
Required permissions
Ensure you've configured Application Default Credentials with the following permissions:
storage.buckets.get
storage.buckets.list
storage.objects.get
storage.objects.list
storage.objects.create
storage.objects.delete
storage.objects.update
SSH proxy¶
dstack-sshproxy is an optional component that provides direct SSH access to workloads.
Without SSH proxy, in order to connect to a job via SSH or use an IDE URL, the dstack attach CLI command must be used, which configures user's SSH client in a backend-specific way for each job.
When SSH proxy is deployed, there is one well-known entry point – a proxy address – for all dstack jobs, which can be used for SSH access without any additional steps on the user's side (such as installing dstack and executing dstack attach each time). All the user has to do is to upload their public key to the dstack server once – there is a dedicated “SSH keys” tab on the user's page of the control plane UI.
To deploy SSH proxy, see dstack-sshproxy Deployment guide.
To enable SSH proxy integration on the dstack server side, set the following environment variables:
DSTACK_SSHPROXY_API_TOKEN– a token used to authenticate SSH proxy API requests, must be the same value as when deployingdstack-sshproxy.DSTACK_SERVER_SSHPROXY_ADDRESS– an address where SSH proxy is available todstackusers, in theHOSTNAME[:PORT]form, whereHOSTNAMEis a domain name or an IP address, andPORT, if not specified, defaults to 22.
Encryption¶
By default, dstack stores data in plaintext. To enforce encryption, you
specify one or more encryption keys.
dstack currently supports AES and identity (plaintext) encryption keys.
Support for external providers like HashiCorp Vault and AWS KMS is planned.
The aes encryption key encrypts data using AES-256 in GCM mode.
To configure the aes encryption, generate a random 32-byte key:
$ head -c 32 /dev/urandom | base64
opmx+r5xGJNVZeErnR0+n+ElF9ajzde37uggELxL
And specify it as secret:
# ...
encryption:
keys:
- type: aes
name: key1
secret: opmx+r5xGJNVZeErnR0+n+ElF9ajzde37uggELxL
The identity encryption performs no encryption and stores data in plaintext.
You can specify an identity encryption key explicitly if you want to decrypt the data:
# ...
encryption:
keys:
- type: identity
- type: aes
name: key1
secret: opmx+r5xGJNVZeErnR0+n+ElF9ajzde37uggELxL
With this configuration, the aes key will still be used to decrypt the old data,
but new writes will store the data in plaintext.
Key rotation
If multiple keys are specified, the first is used for encryption, and all are tried for decryption. This enables key rotation by specifying a new encryption key.
# ...
encryption:
keys:
- type: aes
name: key2
secret: cR2r1JmkPyL6edBQeHKz6ZBjCfS2oWk87Gc2G3wHVoA=
- type: aes
name: key1
secret: E5yzN6V3XvBq/f085ISWFCdgnOGED0kuFaAkASlmmO4=
Old keys may be deleted once all existing records have been updated to re-encrypt sensitive data. Encrypted values are prefixed with key names, allowing DB admins to identify the keys used for encryption.
Default permissions¶
By default, all users can create and manage their own projects. You can specify default_permissions
to false so that only global admins can create and manage projects:
# ...
default_permissions:
allow_non_admins_create_projects: false
Backward compatibility¶
dstack follows the {major}.{minor}.{patch} versioning scheme.
Backward compatibility is maintained based on these principles:
- The server backward compatibility is maintained on a best-effort basis across minor and patch releases. The specific features can be removed, but the removal is preceded with deprecation warnings for several minor releases. This means you can use older client versions with newer server versions.
- The client backward compatibility is maintained across patch releases. A new minor release indicates that the release breaks client backward compatibility. This means you don't need to update the server when you update the client to a new patch release. Still, upgrading a client to a new minor version requires upgrading the server too.
Server limits¶
A single dstack server replica can support at least
- 1000 active instances
- 1000 active runs
- 1000 active jobs.
If you hit server performance limits, try scale up server instances and/or configure Postgres with multiple server replicas.
Also, please submit a GitHub issue describing your setup – we strive to improve dstack scalability and efficiency.
Server upgrades¶
When upgrading the dstack server, follow these guidelines to ensure a smooth transition and minimize downtime.
Before upgrading¶
- Check the changelog: Review the release notes for breaking changes, new features, and migration notes.
- Review backward compatibility: Understand the backward compatibility policy.
- Back up your data: Ensure you always create a backup before upgrading.
Best practices¶
- Test in staging: Always test upgrades in a non-production environment first.
- Monitor logs: Watch server logs during and after the upgrade for any errors or warnings.
- Keep backups: Retain backups for at least a few days after a successful upgrade.
Troubleshooting¶
Deadlock when upgrading a multi-replica PostgreSQL deployment
If a deployment is stuck due to a deadlock when applying DB migrations, try scaling server replicas to 1 and retry the deployment multiple times. Some releases may not support rolling deployments, which is always noted in the release notes. If you think there is a bug, please file an issue.
FAQs¶
Can I run multiple replicas of dstack server?
Yes, you can if you configure dstack to use PostgreSQL and an external log storage
such as AWS CloudWatch, GCP Logging, or Fluent-bit.
Does dstack server support blue-green or rolling deployments?
Yes, it does if you configure dstack to use PostgreSQL and an external log storage
such as AWS CloudWatch, GCP Logging, or Fluent-bit.